This is part 2 of a series about the statistics of global soccer performance, part 1 is here.
A Picture with a Thousand Words on It
The point of this week’s post was to get to this chart, showing how good each country is at soccer independent of population and region of the world:
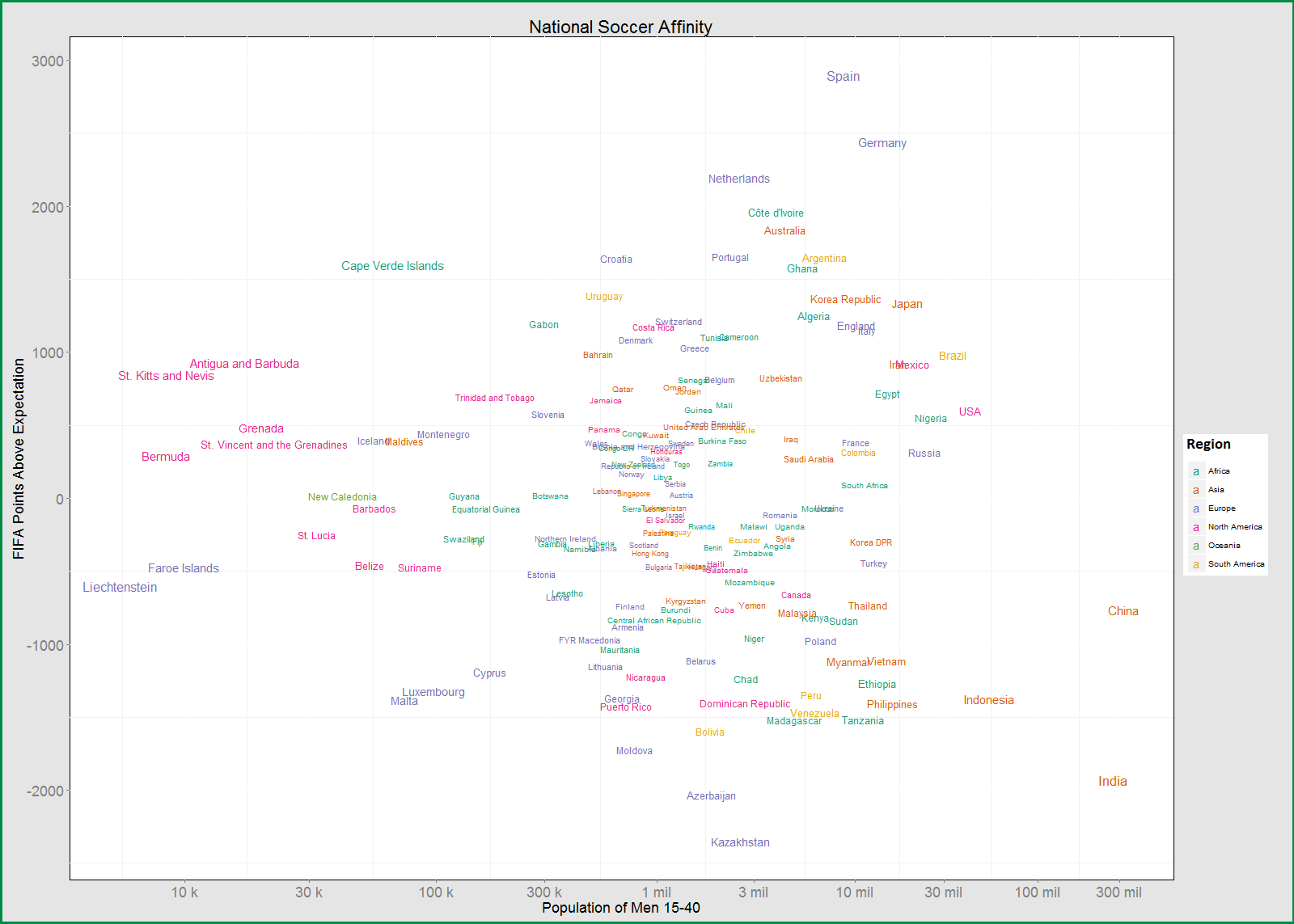
You are encouraged to stare at it until the names blur and Denmark tangoes with Costa Rica across your retinas. It is either the best or the worst chart I have ever concocted, it took forever and gave me a migraine. Here’s the story of how I got to it.
Correlation Does not Imply India
Last week we explored the puzzle of the Chinese national soccer team sucking. Naive calculations showed why it’s surprising that there aren’t 11 players out of 1.3 billion Chinese (or 1.2 billion Indians) that can compete with Iceland. Iceland has 300,000 people and is made of ice (citation needed) which is hard to play soccer on. A better understanding of how the normal distribution works at the extreme tails demonstrated that country population should have a limited effect on national team success. Exactly how limited is that effect in the real world?
The nefarious mob that organizes global soccer is FIFA, which, for being a corrupt cabal of callous criminals, keeps a surprisingly neat database of scores and rankings. Each team accumulates a score based on their result in every game played, the magnitude of the stage and the strength of the opponent. I added up each nation’s scores for the last 11 years (2005-2015) to smooth out fluctuations.
1. Spain – 6930 points
2. Germany – 6401
3. Argentina – 5860
6. Brazil – 5808
22. USA – 4158
65. Cape Verde Islands – 2661
85. China – 2112
152. Liechtenstein – 901
154. India – 887 , with a population of 34,000 Liechtensteins.

I pulled demographics numbers from the UN’s yearbook and painstakingly calculated just the population of men aged 15-40 for soccer team purposes since some countries skew much younger/maler than others.
There are 209 soccer associations in the world (each has an equal vote in FIFA elections regardless of population or contribution, which means bribing the Tahiti delegate gets you as many votes as the USA one, which is how Qatar hosts the 2022 world cup). I cut the bottom ranked 42 nations from consideration because there wasn’t good ranking or population data on most of them. Sincere apologies to my devoted readers in Guinea-Bissau, you just missed the cut of countries I care about.
Here’s a chart of country populations and cumulative soccer points:
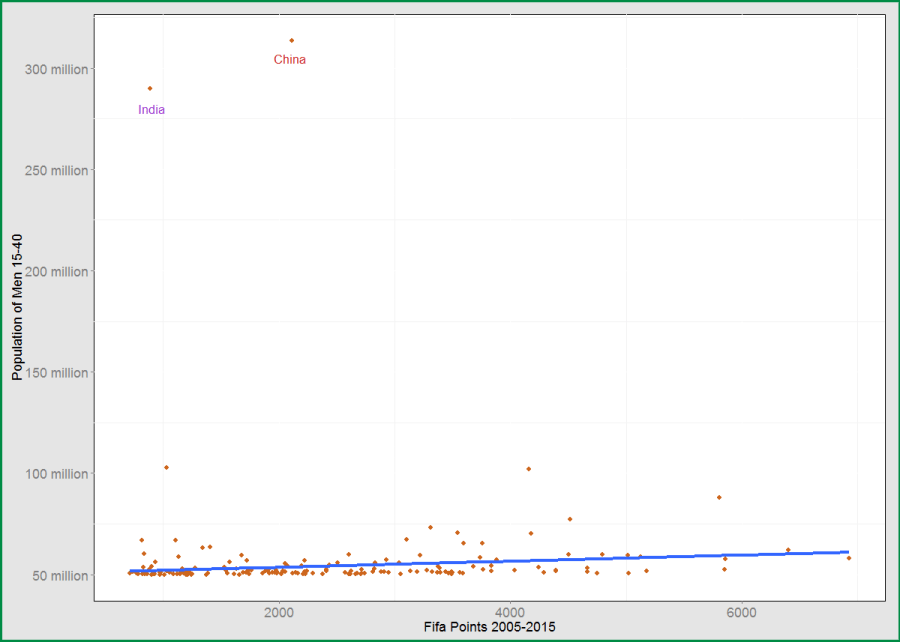
The blue line is the regression between points and population, it shows a slight positive connection. Except that it’s a fake. The regression includes 165 countries but leaves out India and China. Since my goal is to use math to figure out why India and China suck at soccer, I can’t just shout “outliers!” and ignore them. If all 167 countries are included, the correlation between population and soccer rating is an astonishing -0.002, a perfectly flat line.
Correlation measures the tendency of two variables to move together, how much one goes up relative to its own average when the other one does. If two variables are completely independent from each other their true correlation is 0, but if you just simulate 167 values of two independent variables you’ll measure a sample correlation of about 0.05 due to random noise. That tiny noise correlation is 25 times stronger than what we got for population and soccer! The only field that has correlations this small is astrology.
What is going on here?
Hold on, I’m confused about this correlation/regression business.
Then this little section is for you! If you know what those are, move right along.

Correlation tells you if things generally move in the same direction (+1), in opposite directions (-1) or somewhere in the middle. For example, fuel economy for cars has a negative correlation with weight, maybe -0.7. This means that in general, heavier cars are likely to burn through more fuel.
Regression measures the magnitude of the correlation in the units that each variable is measured in. For example, the regression coefficient of car MPG on weight in pounds is -0.01 MPG/lb. The means that every pound added to the weight of a car comes with a 0.01 lower MPG on average, 500 pounds shave off 5 MPG.
Multiple regression measures regression for more than one variable at a time, holding the others constant. Let’s say we see that MPG is lower for heavier cars and for those with larger engines. Multiple regression will tell you that adding 500 pounds by itself only subtracts 3 MPG when engine size is held constant, the other 2 MPG are simply due to heavier cars usually coming with larger engines which hurt fuel economy by themselves. Adding variables (like engine size) can completely change the size and even the sign of all other regression coefficients. Multiple regression also identifies variables that are significant (do a good job of predicting the outcome) and insignificant (those that don’t add anything once the other variables are known).
Regression is the basic tool of a lot of statistical analysis, prediction and machine learning. This Coursera class is one of many good places to learn it.
Six Corners of the World
As y’all know, correlation doesn’t imply causation. What’s often forgotten is that lack of correlation doesn’t imply lack of causation either. Implication is just hard, man. A variable like population could have its effect on soccer rating perfectly cancelled out by other variables, so that when the other variables aren’t accounted for, the correlation is 0.
Here’s an illustration of how that can happen that you can explain to your 5 year old nephew:
- X = number of testicles a human has
- Y = number of ovaries a human has
- Z = number of testicles+ovaries
If we measure across the human race, X and Z would have a correlation that’s very close to 0 since as X goes from 0 to 2 Z stays put at 2 for almost everyone. However, if you were born with 2 testicles, losing either or both of them will have an immediate and directly causal impact on your Z variable.
The average Qatari has 1.53 testicles and 0.47 ovaries, I still can’t get over that.
What’s the ovary to the testicles of country population? (This blog was an excuse to write that line). The first suspect is the region of the world. Asia has 6 of the world’s 10 largest countries, and also some of the ones least interested in soccer. FIFA divides all soccer federations into 6 regions that match geography with some weird exceptions: Europe (includes Israel and Kazakhstan), Asia (includes Australia), South America (only 10 countries), Rest of America (includes America), Oceania (includes Atlantis and the Mermaid Kingdom) and Africa. Teams get points for playing often and against strong opponents, so it’s much easier for a European country to accumulate points than it is for New Zealand, which faces a sparse yearly schedule of Tongas and Vanuatus.
We can tease out the effect of population as independent of region by performing multiple regression with region as an added variable. The verdict is that Europe and South America have a much higher rating than the rest of the world, Asia and Oceania are lower. Holding region constant slightly increases the effect of population because the low rating of China and India is now partially accounted for by the Asia region. However, it’s still insignificant. Ovaries aren’t to blame.
Predictive Slovakiness
Regression measures linear effects, or the change in the effect (points) for a fixed-size change in causes. The effect of population is clearly not linear: adding a million people to a tiny country does much more than adding them to India. Instead of using whole population numbers, we’ll go back to last week‘s normal distribution model in which population affects soccer level by pushing up the quality of the top players, as measured by their distance away from the average. To go from population size to top player level we’ll need to answer the following technical question:
How many standard deviations above the mean will the best 11 players out of a population of N be on average?
It’s possible to answer that question precisely, but I’ll use a good approximation instead: for a country of N people I used as the score the point that has 5/N of the normal distribution above it. Slovakia has around N=1,000,000 men in soccer-playing age. The level that each Slovakian has an exactly 5 in 1,000,000 chance of being better than is the level 4.43 standard deviations above the mean. I took that number (4.43) as the best guess of the relative soccer level of the dudes that contributed to the Slovakian national team over the last decade.

The justification for using that approximation as the measure of population effect is way too rigorous for most readers and way not rigorous enough for real mathematicians; It’s an interesting discussion if you’re into that kind of freaky stuff, but I’m relegating to another post.
We can add the population-expected soccer level as a new variable to the regression to see if it does a better job of explaining the rating of each country. With the soccer level added, actual population size is no longer significant with or without China and India. This means that we can predict a country’s rating pretty well using just the expected level and the region. Here are the regression coefficients, significant in bold:
Intercept: -4748. Intercept is the starting point, it’s the expected rating of a country that has all the other variables set to 0.
Population-expected level: 1474
Africa: 147
Asia:-517
Europe 1529
North America: 508
South America: 1966
The range of countries’ rating goes from 0-7000, the average score is 2440. Going one standard deviation up in the population-expected level is worth a huge boost of 1474 points, but one SD marks a big jump in population: from 10,000 to 600,000 people or from 600,000 to 90 million. Each region’s coefficient measures how many points an average a team from that region is better than Oceania. Europe and Latin America are good at soccer and everyone else isn’t.
The regression can be thought of a prediction, how good we can expect a country to be based just on the variables we look at: expected level of top players and region. The predicted score for a country is calculated by multiplying the coefficient of each variable by the country’s score on that variable.
| Variable | Coefficient | Slovakia’s Score | Change in points |
| Intercept | -4748 | -4748 | |
| Pop-expected level | 1474 | 4.43 | 6532 |
| Europe | 1529 | 1 | 1529 |
| Total score expected from the regression: | 3313 | ||
For example, Slovakia starts from the intercept of -4748 points (like everybody), gets 1474 points for each of 4.43 population-levels and another 1529 points for being in Europe. This comes out to an expected scoreof 3,313 points. Their actual rating is 3,566, so it means that they outperform expectations by 250 points, those points come either from random luck or from some variables that we didn’t account for yet like the famous Slovakian warrior spirit. That’s good news, because otherwise Martin Skrtel would come and stomp on my face for disparaging his great footballing nation. 250 is also a pretty small prediction error compared to the total score, so the Slovariables do a good job of accounting for the Slovariance.
The chart I started with shows how good each country is relative to what we could expect from their region and size. Higher up countries outperform expectations (for reasons we don’t know yet) and those lower down disappoint:
So much fascinating stuff! What do Switzerland and Costa Rica have in common besides being fairly good at soccer with medium populations? Iran and Mexico have similar populations, similar ratings and similar green-white-red uniforms; are they actually the same country? Why does the tiny island of Malta languish, and the tiny Cape Verde Islands kick ass? Is Qatar really good or do they bribe game officials? What makes Spain and Germany kings of soccer in the 21st century? Wait, someone actually wrote an excellent book about the last one.
All the answers (to life, not just soccer ability) are revealed in the riveting conclusion: The Rich, the Tall, and the Bees.

You rock. Probably. We will see.
LikeLike
If you’d read the article you’d linked to you’d have seen that burying infants in the sand was an ancient pre-Islamic practice and that the current gender imbalance in the UAE is due to the large number of predominantly male foreign workers in the country (the article doesn’t explicitly mention what causes Qatar’s imbalance but it’s probably the same). Otherwise, interesting post.
LikeLike
Ostir, you are absolutely correct. I checked another (unlinked) source for the exact gender ratio and I thought it excluded foreign workers from the population statistics. I have edited the article to correct the mistake, please email me putanumonit AT gmail , I owe you a reward!
LikeLike
You need an additional variable in your multiple regression! Number of players representing that country who are actually Brazilian. Deco & Pepe (Portugal), Marcos Senna & Diego Costa (Spain), Eduardo da Silva (Croatia), Zinha (Mexico), Eder (Italy) etc.
LikeLike