Nerdeviations
If we have data, let’s look at data. If all we have are opinions, let’s go with mine. – Jim Barksdale
This blog started with a mathematical analysis of what this blog should be about, and a promise to explain why p-values aren’t part of that analysis. 14 months later, I’m bringing Putanumonit full circle by doing a mathematical analysis of what this post should be about, and explaining in detail why p-values suck.
In case you were worried (or hopeful), bringing the blog full circle doesn’t mean it’s ending. I plan to keep going in a straight line after closing the circle, which should make the entire blog look like the digit 6.
A couple of weeks ago I asked my readers for some greatness-enhancing feedback via survey and email. A lot of the readers who emailed me think that they are much bigger math geeks than the other readers who emailed me, which is pretty funny. But one reader actually proved it by putting a num on it:
I am a huge math nerd, so my interests and knowledge when it comes to this sort of thing are probably at least four standard deviations from the mean of humanity, and at least two from your reader base. – Eliana
Eliana’s email is wonderful for two reasons:
- It says “the mean of humanity” where most people would say “most people”.
- It makes an explicit, testable prediction: that my readers are 2 standard deviations math-nerdier than the mean of the human species.
If math-nerdiness is normally distributed, at +2 SDs my average reader is math-nerdier than 97.7% of humanity. Did you know that math is teens’ favorite subject in high school, year in year out? If normal humans admit (at least in anonymous surveys) to love studying math, surely my readers are on board as well.
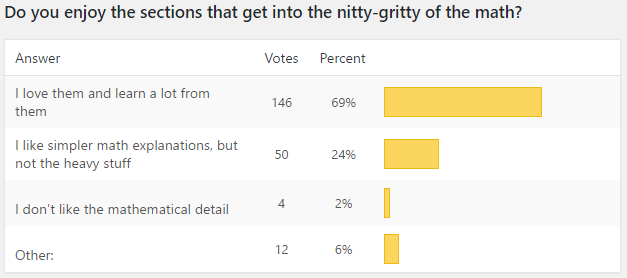
Yep. If I was worried about making Putanumonit too math-nerdy, now I’m worried that it’s not going far enough for my readers. Last week I wrote a post about eating fish and my commenters responded with detailed analysis, math jokes, mental calculation tricks and extensions to famous math puzzles. I feel a bit inadequate, my favorite subjects in school were gym and French.
What’s the point?
The only metrics that entrepreneurs should invest energy in collecting are those that help them make decisions. Unfortunately, the majority of data available in off-the-shelf analytics packages are what I call Vanity Metrics. They might make you feel good, but they don’t offer clear guidance for what to do. – Eric Ries
There’s a point to the opening part of this post, and that’s to demonstrate that data analysis should have a point. The point of the survey above was to help me decide if I should write more or less mathematical detail in my posts, and it doesn’t take much analysis to see that the answer is “way more”. OK then, I certainly will.
We’ll get to some of the other survey results, but I first want to step back and take a broader view of data analysis. In that view, almost all data analysis you see is conducted with one of two goals in mind:
- Drive a decision.
- Get published in an academic journal.
You may have heard of the war raging between the armies of Bayesian and frequentist analysis. Like all global conflicts, this war reached its peak with a clever XKCD comic and its nadir with a sensationalistic New York Times story.
The skirmishes in this war today consist mainly of Bayesians showing frequentists why their methods (i.e. p-values) are either wrong or secretly Bayesian, and salty frequentists replying that the methods work just fine, thank you. In some sense they’re right: as long as academic journals are happy to accept papers based on p-values, getting a p-value is a great way of achieving that goal. It’s the first goal where frequentist analysis suffers, and a more mindful technique is needed.
Properly done, decision-driven analysis should work backwards from the question to the data:
Step 1 – Formulate the question or decision you want to answer with data.
Should I trim my posts to make them shorter or run with longer articles?
Step 2 – Quantify alternative possibilities, or possible answers to the question. Each alternative is a model of how the world looks like in the narrow realm you’re interested in. The goal of the data is to promote one of the alternatives above the rest, so each alternative should correspond to a decision option or an answer to the main question.
Going from the decision I want to make, I will change the length I aim for in my posts if every fourth additional reader will be pleased by it. Specifically:
Alternative 1 – I would write longer posts (decision) if 25% more of my readers prefer longer posts to shorter ones (possible world).
Alternative 2 – I would write shorter posts (decision) if 25% more of my readers prefer short posts to longer ones (possible world).
Alternative 3 – I would keep the same length of posts (decision) If about the same percentage of readers like and dislike long posts (possible world).
It’s very likely that actual gap between lovers of long and short posts will fall somewhere between 0% and 25%, but I’m not interested in precisely estimating that gap. I’m only interested in making a decision, and since I have three decision options I can make do with only 3 alternatives. I will make the decision based on the alternative that seems most likely after everything is accounted for.
Step 3 – Put a number on how likely each alternative is. This should be based on your background knowledge, whatever information you have before the new data comes in. This is called the prior, and for some reason it makes more people uncomfortable than Richard Pryor. We’ll get to both later.
My most popular posts were on the longer side, but not overwhelmingly so. I think people probably like both the same, and maybe lean towards longer posts. My priors are 30% for Alternative 1 that longer is better (that’s what she said), 10% for Alternative 2 and 60% for Alternative 3.
Step 4 – Use the new evidence to update your prior probabilities in accordance with Bayes’ rule and arrive at the posterior, or the outcome. Make your decisions accordingly.
The verbal logic of Bayes’ rule is that whichever alternative gave the highest probability of seeing the evidence we actually observed is the one most supported by the evidence. “Support” means that the probability of the alternative increases from its prior. I’m going to demonstrate the use of Bayes’ rule, but I’m not going to explain it further. That’s because Arbital’s guide to Bayes’ rule does such an excellent job of explaining it to any level of skill and need that I don’t want to step on their turf. If you have any doubts, big or small, about what the rule says and why it works go ahead and spend some time on Arbital. I’m not going anywhere.
You’re back? Good. I assume you’re hip to Bayes now and we can jump straight into the calculation.
We have three competing hypotheses and prior probabilities on all three. I’m going to summarize the prior probabilites in odds form, because that’s the easiest form to apply Bayes’ rule to. Our odd ratios for Alternative 1 (longer is better):Alternative 2 (shorter):Alternative 3 (same) are 30%:10%:60%, or 3:1:6.
All we need now is the evidence. I have combined a couple of survey question and their responses to get this basic breakout:
| Longer is better | 131 | 34% |
| Equally good | 183 | 47% |
| Shorter is better | 72 | 19% |
| Total | 386 | 100% |
The gap between people who prefer longer posts to shorter ones is 34% – 19% = 15%. That wasn’t one of our three alternatives, but it’s definitely closer to some than to others. Ideally, instead of picking a few discrete possibilities we will have a prior and a posterior on a continuous distribution of some parameter (like the long-short gap). I’ll go through a continuous-parameter analysis in the next post.
We now need to calculate the probability of seeing this result given each of the three alternatives, P(131-72 long-short split | alternative N). I whipped up a very quick and dirty R simulation to do that, but with a couple of assumptions we can get that number in a single Excel line. To make life easy, we’ll assume that the number of people who show no preference is fixed at 183 out of the 386, so our alternatives boil down to how the other 203 readers are split.
Alternative 1 – There’s a 25% advantage to long posts, and 25% of 386 responders is 97. So this alternative says that out of the 203 who show a preference, 97 more will prefer long posts. This means that these 203 readers will be split 150 in favor of long, 53 in favor of short. 150/203 is 74%, so this alternative predicts that 74% of 203 prefer long posts.
Similarly, Alternative 2 says that 53 of 203, or 26% prefer long posts, and Alternative 3 says that 50% of them do (i.e. an equal number prefer long and short). Now we simply treat each responder as making an independent choice between long and short with a fixed probability of 74%, 50% or 26%. For each option, the chance of getting our observed 131-72 split is given by the binomial distribution which you can calculate in Excel or Google Sheets with the BINOMDIST function.
P(evidence | Alternative 1) = P(131 long – 72 short | 74% for long) = BINOMDIST(131,203,0.74,0) = .0007
P(evidence | Alternative 2) = P(131 long – 72 short | 26% for long) = BINOMDIST(131,203,0.26,0) ≃ 0, as far as Google Docs can calculate. Let’s call this ε.
P(evidence | Alternative 3) = P(131 long – 72 short | 50% for long) = BINOMDIST(131,203,0.5,0) = .0000097
The likelihood ratios we get are 0.0007 : ε : 0.0000097 = 72:ε:1. We’ll deal with the ε after calculating the posterior odds.
Posterior odds for alternatives 1:2:3 = prior odds * likelihood odds = 3:1:6 * 72:ε:1 = 216:ε:6. We can go from odds back to probabilities by dividing the odds of each alternative by the total odds. 216 + 0 + 6 = 222 so:
Probability that a lot more people prefer long posts = 216/222 = 97%.
Probability that an equal number prefer long and short posts = 6/222 = 3%.
The probability that a lot more people prefer short is bounded by the Rule of Psi we formulated in the last post:
Rule of Psi (posterior edition)- A study of parapsychological ability to predict the future produced a p-value of 0.00000000012. That number is only meaningful if you have absolute confidence that the study was perfect, otherwise you need to consider your confidence outside the result itself, i.e. the probability that the study is useless. If you think that for example there’s an ε chance that the result is completely fake, that ε is roughly the floor on your posterior probabilities.
There’s at least a 0.1% chance that my data is useless. Either I formulated the questions wrong, or the plugin didn’t count them, or someone who loves long posts voted 200 times to confuse me. This means that we shouldn’t let the data push the probability of any alternative too far below 0.1%, so we’ll set that as the posterior for more people preferring short posts.
Our simple analysis led us to an actionable conclusion: there’s a 97% chance that the preference gap in favor longer posts is closer to 25% than to 0%, so I shouldn’t hesitate to write longer posts.
What’s important to notice is that this decision is driven completely by the objective evidence, not by the prior. Let’s imagine that prior had been pretty far from the truth: 10% for longer posts, 45% for shorter, 45% for equal. The posterior odds would be: 10:45:45 * 72:ε:1 = 720:ε:45. The evidence would take Alternative 1 from 10% to 720/765 = 94%. I would have had to give the true alternative a tiny prior probability (<1%) for the evidence to fail to promote it. 30%:10%:60% was a pretty unopinionated prior, I made all the probabilities non-extreme to let the evidence dictate the posterior.
The prior doesn’t have to be perfect, it just needs to give a non-tiny probability to the right answer. When using Bayesian inference, sufficient evidence will promote the correct answer unless your prior is extremely wrong.
Bottom line: the evidence tells me to write long posts, which the survey defined as having 3,000 words. I’m only 1,800 words in, so let’s take a second to talk about art.
The Art of Data Science
A lie is profanity. A lie is the worst thing in the world. Art is the ability to tell the truth. – Richard Pryor (I told you we’d get back to him)
I chose this quote not just because of Pryor’s very Bayesian surname, but also because I wanted to write the first essay ever that quotes both Richard Pryor and Roger Peng, two men who share little in common except for their initials and a respect for truth. Peng created the JHU data science specialization on Coursera (well explained and not very challenging) and wrote The Art of Data Science. Here’s how he explains the title of the book:
Much like songwriting (and computer programming, for that matter), it’s important to realize that data analysis is an art. It is not something yet that we can teach to a computer. Data analysts have many tools at their disposal, from linear regression to classification trees and even deep learning, and these tools have all been carefully taught to computers. But ultimately, a data analyst must find a way to assemble all of the tools and apply them to data to answer a relevant question—a question of interest to people.
I made several choices in the previous section that could all be made differently: picking the three alternatives I did, or using a simplified binomial distribution for the likelihood. I made these choices with the goal of trying to tell the truth. That involves getting close to the truth (which requires using good enough methods) and being able to tell it in a comprehensible way (which requires simplifying and making assumptions).
The procedure I outlined isn’t close to the Bayesian ideal of extracting maximum information from all available evidence. It’s not even up to industry standards, because unlike many of my readers I am not a professional data scientist (yet, growth mindset). But the procedure is easy to emulate, and I’m pretty sure the answer it gave me is true – people want longer posts.
And yet, this is very useful procedure is only taught in the statistics departments of universities. Cross the lawn and you’ll find that most other departments, from psychology to geology, from business school to the med school, teaches something completely different: null hypothesis testing. This involves calculating a p-value to reject or accept the mythical “null hypothesis”. It’s a simple method, I learned it well enough to get a a perfect score on the statistics final, and the following year I helped indoctrinate new students into null hypothesis testing as a teaching assistant. But since then I spent a good while thinking about it, and I came to realize that null hypothesis testing is hopelessly inadequate in getting close to the truth.
The Null Method
Null hypothesis testing fails to divulge the truth for three main reasons:
- It asks “is the null hypothesis accepted or rejected?”, which is the wrong question.
- It calculates a p-value, which is the wrong answer.
- Both the null and the p-value aren’t even relevant to what the truth actually looks like.
These are some bold claims, so let’s inspect them through the example of a serious research study, and not just my piddling survey. Here’s a study about differences in intelligence between the first and second-born sibling. What does null hypothesis testing make of it?
Hypothesis testing only knows to ask one question: Is the null rejected? The answer to this is a resounding “yes”: Older siblings are smarter because the null hypothesis of equal IQ between siblings is rejected with a p-value of 0.00000001. So many zeroes! Hold on while I call my younger brother to inform him of my intellectual superiority.
But wait, isn’t a better question to ask is: How much smarter are older siblings? The answer is 1.5 IQ points. That is smaller than the 4-6 point average difference between two IQ tests taken by the same person two years apart. It’s a mere fraction of the 30 point hit a person’s IQ takes the moment they start typing in a YouTube comment. The answer to the better question is: imperceptibly.
Another question could be: What are the chances that in a given family the older sibling has higher IQ? The answer to that is 52%, practically a coin flip. Any relevant information will tell you more about relative IQ than birth order, for example the fact that my brother studies chemistry and writes poetry, while I got an MBA and write about Pokemon.
So how did the study get such an impressive p-value? Because their sample size was 3,156. With such a huge sample size, you can get “statistical significance” with or without actual significance. Whatever your goal was in studying birth order and intelligence, answering “is the null hypothesis rejected?” is usually useless in achieving that goal.
The answer you get, a p-value, is pretty meaningless as well. Does a p-value of 5% means that you’re wrong in rejecting the null 5% of the time? Nope! You’re going to be wrong somewhere between 30% and 80% percent, depending on the power of the study. Does it even mean that if the null is true you’ll see the same result 5% of the time? Nope again! That’s because the p-value is calculated not as the chance of seeing the actual effect you measured, but as the chance of getting a result at least as big (technically, as far from the null) as the measured effect.
Calculating anything for the group of “effects at least as big as the measured effect” is absurd for two reasons:
- This group isn’t representative of the measured effect because the measured effect is an edge case within that group. In the IQ example, the p-value is the chance, given that the null is true and also given a bunch of assumptions, that the older sibling is smarter by 1.5 points, or 2 points, or 27 points, or 1500 points. It’s a huge range of outcomes, most of which are a lot farther away from 1.5 than 1.5 is from 0 (the null). If we assumed 0 and got 1.5, why are we calculating the probability of getting 27?Moreover, the assumptions that underlie the p-value calculation (such as a normal distribution) are very hard to justify over that huge range of 1.5 to infinity. Many distributions resemble a normal bell curve close to the middle but look very different in the tails. The “range of IQ differences bigger than 1.5” (the right tail) looks little like the data we actually have which is “an IQ difference of exactly 1.5”.
- This group for the most part doesn’t even include the actual effect, which is usually smaller than the measured effect. If you measured a positive effect, the measurement error was likely in that positive direction as well. When we subtract the error from the measured result to get the true result, we get a small number which is completely outside the range of the bigger numbers we measured the p-value on.
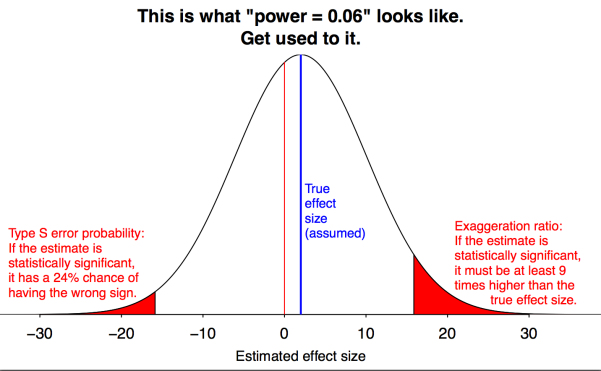
The lower the power of the experiment, the worse this problem gets, and power is often pretty low. With the graph below Andrew Gelman shows just how bad this gets when the statistical power = 0.06, which is what the “Ovulating married women vote Republican” study had:
This is why in the likelihood calculation I used the precise result of “exactly 131 people prefer long posts”, not “131 or above”. P-value calculations don’t work with point estimates, but “or above” ranges will break even likelihood calculations.
Let’s try this on the survey results. If we tried null-rejection testing, whether I chose “50% prefer long posts” or “74% prefer long posts” as my null hypothesis, the actual result of “131/203 prefer long posts” would reject the null with p<0.002. Again, rejecting the null doesn’t tell you much.
When I calculated the likelihood given by “131 prefer long”, I got a ratio of 72:1. If instead I had calculated the likelihood based on “131 or more prefer long”, the likelihood ratio in favor of Alternative 1 would have been 47,000:1. Here’s the fun part: if I had looked at “131 or below”, the likelihood ratio would have been 1:1730 in favor of the opposite alternative!
Choosing a direction for the range of outcomes can arbitrarily support any hypothesis you come up with, or reject it. But that’s exactly what having a single null hypothesis does, it defines an arbitrary direction: if the measurement landed above it you look at that result or above, and vice versa. That to me is the main issue with null hypothesis testing – a single hypothesis with no alternatives can’t bring you to the actual answer.
When you have several alternatives, gathering more evidence always brings you closer to the truth. “25% more people like long posts” isn’t the exact truth, but it’s probably closer than the other two options. When you have a continuous distribution of alternatives, you do even better as the evidence zeroes the posterior in on the real answer.
But if you just had one null and you rejected it, your conclusions depend more on the choice of null (which can be quite arbitrary) than on what the evidence tells you. Your company released a new product and it sold 10,000 copies, is that good or bad? That entirely depends on whether your null hypothesis was 5,000 copies or 20,000. Should the null hypothesis be the average sales for any product your company makes? But this product had a smaller niche, a larger advertising budget, and twice the R&D cost. It makes no sense to compare it to the average.
The best you can do is to incorporate all available information about the customers, the price, the advertising and the cost. Then, use all those factors to calculate a predicted sales volume, along with a range of uncertainty around it. But that’s not a null hypothesis anymore, that’s the prior, the one that frequentists don’t like because it feels subjective.
Null-worship isn’t a strawman, it happens to Nobel-caliber scientists. If you remember my essay about hot hand shooting, Tom Gilovich and Amos Tversky hypothesized that basketball players shoot 0% better on their second free throw, and made that the null hypothesis because 0 is a nice round number that pretends to be objective. A bunch of random fans estimated the difference to be 8%. The actual answer came out to 4%, and the scientists concluded that there’s no improvement because their sample was too small for the null to be rejected at p<0.05!
In absolute terms, both fans and scientists were off by 4%. In relative terms, the fans overestimated the effect by a factor of 2, while the scientists underestimated the effect by a factor of infinity. Gilovich and Tversky didn’t declare victory because they were closer to the truth, but because they got to pick the null.
Is there any use to null hypothesis testing at all? Yes, but it’s the opposite of how most people use it. In common practice, if someone rejects the null, they declare victory and publish. If they don’t reject the null, they p-hack until the null is rejected and then declare victory and publish.
Instead, null hypothesis testing can be a quick check to see if your data is worthwhile. If you fail to reject the null, your data isn’t good enough. There’s too much noise and too little signal, you need better data or just a lot more of it. If you do reject the null, your data might be good enough to yield an answer once you throw out the p-value and start doing some actual statistical inference.
Summary
This post was nerdy, and it was long, and it’s time to wrap it up.
Data analysis is both an art and a science. There’s no single recipe for doing it right, but there are many ways to do it wrong, and a lot of the latter ways involve p-values. When the questions falls to you, stick to a simple rulebook:
Rule 1 – Focus on the ultimate question you’re answering, the one that drives the decision. For every step in the analysis, ask yourself – is this step helping me answer the ultimate question?
Rule 2 – Before you see the data, come up with alternative hypotheses and predictions. Base these predictions on your knowledge of the issue, not on objective-looking round numbers.
Rule 3 –

Featured image credit: Shadi Yousefian

Good explanation. Now that I’ve read the Undoing Project I’m a bit surprised by Tversky making these mistakes, they gave the impression that he was the original “we need better statistical practices” guy.
I understand why you’d expect the measurement error to be in the same direction as your effect size, but not why the estimate would have to be 9 times greater than the true effect size to be measured.
(Also, I think you meant to replace the paragraph that starts “And yet, this isn’t the common procedure that is taught at every university department except for the school of statistics.” with the one after it? Or did I misunderstand that whole part?)
LikeLike
Thanks, that half-paragraph got through Putanumonit’s very rigorous editing process :)
I added the explanation for the Gelman graph, it shows the specific case where the experimental power is 0.06, which it was for the study that concluded that ovulating married women are likelier to vote for Romney but ovulating single women for Obama. When the power is that low all you’re measuring is noise, so even if the effect exists the noise is 9 times higher.
LikeLike
Thanks for the post.
I found your Bayesian analysis problematic. As you point out, data science is an art. You postulated a universe where the only three possibilities were (1) exactly 25% more of your readers preferred longer posts, (2) exactly 25% preferred shorter posts, (3) exactly 183/386 readers have no preference, and the remaining readers are IID 50% likely to prefer longer or shorter. Ignoring the minor issue that by fixing the number of readers with no preference you’ve mixed up your hypothesis generation process and your observation process, this analysis is at odds with your purpose. You correctly state that data analysis should have a point, and in your case, you stated that your criterion for deciding to write longer posts is “I would write longer posts (decision) if 25% more of my readers prefer longer posts to shorter ones (possible world).” The actual data doesn’t support this — the conclusion was heavily driven by your poor choice of hypothesis space.
The key tipoff here is that the total probability of the evidence is tiny. In the world of the three alternatives you suggested, the data you observed is exceedingly unlikely: under your prior it’s basically .3*.0007 = .00021. On the other hand, if you’d offered a 15% preference as a hypothesis, even with a fairly low prior, that would have dominated the posterior, because [in your language, I’m using python] BINOMDIST(131,203,0.59,0) = .0158, and ,0158 / .0007 is about 23.
The right way to do the analysis is of course with continuous parameters, but even with discrete, your conclusion isn’t sensible, because you’re forcing yourself to choose between alternatives that are very very far from the observed data. Yes, it’s much more plausible that 25% more of your readers prefer longer posts to shorter posts than 0%, but any analysis that offers an intermediate choice like “10-15% of readers prefer longer posts” is going to dominate, and since you were basing your decision on the 25% number, I think you’ve reached the wrong conclusion here.
LikeLiked by 2 people
Rif, thank you for taking the time to dig into the math.
What you wrote makes a lot of sense if I was trying to answer the question that most people would: “what is the preference gap between long and short post lovers?” That gap came out to 15.2%, and maybe if we did full inference with a prior that was weighted towards 0 the best estimate would come out to 14.3% or something. What do I do with 14.3%? That’s not what I was looking for.
I didn’t care what the precise estimate is, but whether I should write longer posts. The actual answer the data gave me is “the real gap is almost certainly (72:1) closer to 25% than it is to 0%“, and ahead of time I made the call that I would interpret that as encouraging me to write longer posts. I was making a trinary decision, so I had three alternatives – one for each decision. An alternative of “10-15%” would have been closer, but it wouldn’t help me make a decision. Perhaps you think that my decision rule is poor, but the analysis gave me the answer to the question I was actually asking.
Your point about mixing hypothesis generation with observation is a valid one, but I wasn’t sure how I could avoid it without estimating a full model of all the parameters (which I’ll try to do for the next post) or having a cumbersome monstrosity of 9 or 29 discrete options. I played around with this a bit in my simulations, and letting the % of “undecided voters” vary didn’t affect the outcome too much, so I decided to simplify for the sake of readability. The main goal of my post was to contrast Bayesian inference with null hypothesis testing, not to prove anything in particular about long or short posts.
LikeLiked by 1 person
Thanks for the response!
I agree completely that the real gap is almost certainly closer to 25% than 0%. But what you actually wrote was “Alternative 1 – I would write longer posts (decision) if 25% more of my readers prefer longer posts to shorter ones (possible world).” To me, this implies that if the number were only 15%, you would not write longer posts. Am I misinterpreting?
By not mentioning any of this, it really seems like you’re concluded that the gap is 25%, when in fact the data only shows it’s closer to 25% than 0%. If you had instead phrased alternative 1 as “I would write longer posts (decision) if the fraction of readers preferring longer posts were closer to 25% than 0%,” and had some discussion of these issues, I think the analysis would be a lot stronger. Maybe you want to update the alternatives in the writeup? Or maybe you feel that your writing of the alternative already implies what you wanted? I do think it’s worthwhile to get this right, since you are teaching people about the art of data analysis.
Thanks again for your post.
LikeLike
I guess you’re right, the fact that I had to explain myself in a long comment meant that the post itself wasn’t clear enough. I added some explanation in the post itself of what exactly I’m doing.
LikeLike
Something that confuses me after reading these specific comments is why is the standard for wanting longer posts should be if 12.5% more of respondents want longer posts then want shorter posts. Ignoring the respondents who want posts the same length, if 56.25% of respondents want longer posts and 43.75% of respondents want shorter posts, I would keep posts the same length especially if one considers the random and systematic uncertainties in this analysis. My standard would be (if asking how to change the length of my posts) if I can be highly confident that more then 25% of people prefer one option over each of the other two (that is more then a 50% 25% 25% split) then the survey says that I should stick with that option. If I can’t get data that suggests that there is a strong preference for a greater frequency for of the three types of posts then I would use another analysis. Getting a likely answer of around 15% more people prefer longer posts then prefer shorter posts is not strong evidence, in my opinion, that you should write longer posts more frequently.
I would ultimately say that if the goal was to figure out how to adjust the frequency of your posts between long and short posts, you collected the wrong data. Instead of asking readers to chose between which posts they like more I would have asked how they feel about each (like you did on the subject mater questions). Perhaps with a 5 point scale where 1 is “they make me want to stop reading this blog” and 5 is “they make me want to keep reading this blog” and allow respondents to give partial answers (like 3.2). I would then calculate which frequency of blog posts (between the two) maximizes readership. With the three option for the three different topics, one could get data about what the frequency between these should be. This is harder to do without being able to correlate responses (that is if someone answers they all make one want to read the blog more) but one can still use this data, data from readership statistics, and other sources of data (personal feedback) to adjust the frequency of particular posts.
This said, it is still a valuable example of a Bayesian analysis that answers the specific question: “is the number of people who prefer longer posts to shorter posts closest to 25% 0% or -25%.” This is not as valuable an example of using data analysis to answer a specific policy question. Sometimes even intelligent people collect data they think will be helpful but turns out it wasn’t the right data. Collecting surveys has a cost (some readers like answering them, some consider it a chore) and sometimes collecting new, better data, is not an option. Decision makers still have to make decisions. Discussing these issues would be better then saying that “between 12.5% and 25% of readers prefer longer posts to shorter posts so therefore I should write longer posts more frequently,” if that is what you’re saying.
LikeLiked by 1 person
I agree with pretty much everything you wrote here. I spent about 5 minutes phrasing the survey questions and then 5 hours doing the analysis. I readily admit that it’s a really stupid ratio of effort.
For next year, I’ll actually read a book on survey design and write about that :)
LikeLike
I’m sorry for the double post. Apparently having indentations creates formatting problems. I have learned not to put indents when I comment on this blog. Please feel free to delete whichever post is harder to read.
I’ve gone back and used the data to both answer the question I raised and to answer Mr. Falkovich’s question. I suppose that everyone who reads Put A Num On It either wants the blog to be predominantly longer posts (I label the portion of readers who fit in this category l), predominantly shorter posts (s), or who want a good mix (e for equal). I take these values to be the true value and that l+s+e=1 that is anyone who reads Put A Num On It would fit into one of these categories (I suppose someone could read the blog but wishes that Mr. Falkovich would not write anything). I do this to make things simpler and the survey question only considered these three categories.
The survey served to get some data on what l, s, and e are but the results will likely not match the numbers perfectly. One reason for this is if more members of one group would be more likely to see the survey between when it was posted and when Mr. Falkovich collected data from it. If there is one reason to suspect that one group would more likely see the survey in this time (say that someone who likes the longer posts but not the shorter posts would check the blog less frequently as they would only be interested in reading the longer posts which are spaced out) then this would be a systematic error. The random chance that one person may miss seeing the survey for any reason in this time regardless of what category they belong to would be a sample error. There are other sources of both types of error and to do the analysis correctly I would need to measure the systematic error. I am too lazy to do that (it’s hard to do) and will assume the systematic error is zero thus the only error in the differences between the survey values and the true values will be due to the sample error. The multinomial distribution will take care of the sample error in my analysis.
* To have it in a clear place the result of the survey is 131 people want the blog to be predominantly longer posts, 72 people want the blog to be shorter posts, and 183 want a mix. This isn’t exactly what the question asks but it’s close enough for this demonstration (and answer). Notably the entire number of people who took the survey is 386. I will define R:=(131,72,183). That is the results of the survey is a triple of the number of people who answered in each category.
The first question I ask is either l>s+.25 and l>e+.25 or s>e+.25 and s>l+.25. I treat each of the “or” elements separately. That is I’m interested if the portion of readers who want predominantly longer posts is 25% greater than both those who want the blog to be predominantly shorter posts and those who want a good mixture. I’m also interested in the same except for those who want predominantly shorter posts. The l>s+.25 ⋀ l>e+.25 condition is the first alternative and I label that A_1 while the s>e+.25 ⋀ s>l+.25 condition is the second alternative and I label that A_2. Any other possibility is the third alternative that I label A_3. This (A_3) will be true if either a good majority prefers to have a balance of posts or if there is not a good majority of readers preferring any of the three options with respect to the others.
I give myself a number of different priors just to see what happens in each (it turns out they don’t give substantially different results). I label each prior in the form S_i and is a three tuple of the relative likelihood that A_1, A_2, or A_3 is the case. These priors are S_1=(1,1,1) (someone who has no clue which one is more likely before the survey data), S_2=(3,1,6) (someone who thinks that it is more likely that people only long posts rather than want only short posts but who thinks it’s more likely still that there is no preference), S_3=(1,1,5) (someone who strongly thinks that there will be no clear preference), S_4=(1,6,2) (someone who is confident that most people clearly want to see only short posts), S_5=(2,2,1) (someone who thinks there will be a clear opinion but doesn’t know what that will be).
* First it’s important to note that since l+s+e=1, e=1-l–s thus I am dealing with a two dimensional probability space. l and s are free to very within certain constraints and if one knows these two values then one knows e. The constraints are l≥0, s≥0, and l+s≤1 ⇔ l≤1-s.
* Now, in order to apply Bayes’ inference, we need to find the adjustments based on the survey results. Given particular values for l and s the chances that the survey would return its exact results are given by the multinomial distribution and is 386! / (131! * 72! * 183!) * (l)^131 * (s)^72 * (1-l–s)^183 . Note that this gives a 314 degree polynomial in l and a 255 degree polynomial in s if I were to do the expansion but I don’t have to so I won’t. Since the constant terms appear in every calculation I make without changing, I can ignore it (the Bayes vectors are equivalent when multiplied by a scalar (constant)). I define z(l,s):=(l)^131 * (s)^72 * (1-l–s)^183 .
In order to use Bayes’ inference, I must know the probability of getting R for each of the alternatives. The condition for each alternative is not a single point (as Mr. Falkovich did in his analysis) but rather a region. In order to find this probability, I take the average probability for the region of probability space representing each alternative. I take the average to correct for the measurement bias of having regions of different areas (that is if one alternative has “more” values of l and s that satisfy it then that itself increases the likelihood that the survey will be more consistent with that alternative). The optional paragraph bellow gives more motivation for doing this (as does, I claim, a formal treatment of Bayesian analysis).
(Optional Paragraph) Suppose I had two alternatives: that both l and s are both less than one percent and everything else. Also, my survey got zero results. The results for the survey would be 0! / (0! * 0! * 0!) * (l)^0 * (s)^0 * (1-l–s)^0 = 1 . This means that no matter the values for l and s that I use, there is a 100% chance the survey would have goten the results it got given the number of people who took it. Since no one took the survey, I have nothing to use to update my priors and my prior beliefs should persist. This means that the likelihood ratios need to be equal and the way to do this is to take the average probability in each alternative’s area.
I need to find the area’s each alternative represents in order to do the likelihood calculation. For A_1, l≤1-s, l>s+.25, and l>e+.25 ⇔ l>1-l–s+.25 ⇔ l>.625-s/2 . From, l>s+.25 and l≤1-s one gets that s<.375 and s≥0 of course. Of note, s+.25=.625-s/2 ⇔ s=.25 and l>.5 . Because the conditions for A_2 are symmetric to the conditions for A_1 the area for A_2 is just the area for A_1 with the ls and ss reversed. This is true even though z is not symmetric in l and s. This later fact will yield different average probabilities. For completeness, 1-s=.625-s ⇔ s=.75 which is outside of the range.
* I am now ready to define the relative likelihoods from R of each alternative. I define a_i to be the relative likelihood to A_i. a_1 is the sum of two double integrals divided by the sum of two double integrals. The numerator is the integral from 0 to .25 of s of the integral from .625-s/2 to 1-s of l of z(l,s) plus the integral from .25 to .375 of s of the integral from s+.25 to 1-s of l of z(l,s). The denominator is the integral from 0 to .25 of s of the integral from .625-s/2 to 1-s of l of 1 plus the integral from .25 to .375 of s of the integral from s+.25 to 1-s of l of 1. (If there was a systematic error, say those who want predominantly longer posts are 10% less likely to take the survey, then the integrand in the detonator would not be 1 but would be a function of l and s.)
* Similarly a_2 is the sum of two double integrals divided by the sum of two double integrals. The numerator is the integral from 0 to .25 of l of the integral from .625-l/ to 1-l of s of z(l,s) plus the integral from .25 to .375 of l of the integral from l+.25 to 1-l of s of z(l,s). The denominator is the integral from 0 to .25 of l of the integral from .625-l/2 to 1-l of s of 1 plus the integral from .25 to .375 of l of the integral from l+.25 to 1-l of s of 1.
* a_3 is also a quotient. The numerator is the integral from 0 to 1 of l of the integral from 0 to 1-l of s of z(l,s) minus each of the numerators of a_1 and a_2. The denominator is the integral from 0 to 1 of l of the integral from 0 to 1-l of s of 1 minus each of the denominators of a_1 and a_2.
I used Wolfram Alpha to do the integrals and Excell to do the rest of the calculations. I am giving the values for the relative likelihoods to three figures though I used 6 in the calculations. a_1=1.7910^-192, a_2=3.6910^-215, a_3=4.39*10^-176. The relative likelihood for the third alternative is 16 orders of magnitude grater then it is for the first alternative and even more for the second. For all of my prior’s this means that there is a greater than 99% chance that there is no consensus amongst readers on having anything other than a mix of short and long posts and thus I urge Mr. Falkovich to include a mixture of short and long posts. In fact, one would need a prior probability that anything other than readers wanting predominantly long posts of less than one trillionth of a percent for this data to provide at-least a 50% posterior probability of readers wanting predominantly longer posts.
Now that I’ve answered mine (and Mr. Falkovich’s root question) I can use this same process to answer the question: is the portion of readers who prefer predominantly long posts closer to being 25% greater than those who prefer predominantly short posts then equal, vice versa, or are the portions closer to being equal then either other option. This corresponds to the alternatives that Mr. Falkovich used in his post. I will label new alternatives A_i to be A_1 is when l>s+.125, A_2 is when s>l+.125, and A_3 to be any other condition.
While Mr. Falkovich found the expectation using specific values for l and s that are in the respective regions, I will be finding the average probabilities in the entire regions using the same method as above. We should get similar but different results.
In this case a_1 is just the quotient of two double integrals with the numerator being the integral from 0 to .4375 of s of the integral from s+.125 to 1-s of l of z(l,s) and the demoninator is the integral from 0 to .4375 of s of the integral from s+.125 to 1-s of l of 1. a_2 is just the quotient of two double integrals with the numerator being integral from 0 to .4375 of l of the integral from l+.125 to 1-l of s of z(l,s) and the denominator is the integral from 0 to .4375 of l of the integral from l+.125 to 1-l of l of 1. a_3 is the calculated the same as above.
From this I have a_1=5.6210^-176, a_2=2.2210^-189, and a_3=2.72*10^-176. The priors I would consider were S_1=(1,1,1), S_2=(3,1,6), S_3=(1,1,5), S_4=(1,6,2), and S_5=(2,2,1). I will get a triple of posterior probabilities from each prior odds and I will list them as percentages. For example from S_1 I get (67%,<1%,33%) which means that after this evidence, I would give a 67% chance that l is closer to being .25 grater then s then it is to equal and a 33% chance that l is closer to being equal to s then it is to being closer to .25 different.
For the different priors, I would get S_1 yields (67%,<1%,33%), S_2 yields (51%,<1%,49%), S_3 yields (29%,<1%,71%), S_4 yields (51%,<1%,49%), S_5 yields (81%,<1%,19%). The prior that Mr. Falkovich used in his analysis was S_2 the fact that we got vastly different answers is an indication that at-least one of us did something incorrect. Since I’m new to Bayesian analysis that suggests that I did but there is one key methodological difference that could explain it. Mr. Falcovich only considered differences between l and s while I allowed for varying values for e.
If I keep e constant at e=183/386 then s=1-183/386-l. I now have a one dimensional problem. In this case, l>s+1/8 ⇔ l> 9/16-183/772 and similarly, l<s-1/8 ⇔ l< 7/16-183/772. Calculating a_i then becomes a single integral on these intervals (there is an upper limit to lof 1-183/386) (I still have to divide by the length of the intervals). I get (using Wolfram Alpha and Excell), a_1=1.6610^-173, a_2=3.1010^-187, and a_3=7.74*10^-175.
From the different priors, I would get S_1 yields (68%,<1%,32%), S_2 yields (52%,<1%,48%), S_3 yields (30%,<1%,70%), S_4 yields (52%,<1%,48%), S_5 yields (81%,<1%,19%). This is almost identical to the situation where I considered different possible e values with a slight increase in the chances of A_1. Either one of us did our math wrong, doesn’t understand what we’re doing, or the decision to take a single reprehensive point from each region rather than the average of all points makes a noticeable difference.
Assuming I did the process correctly, the survey does not do much to differentiate whether l–s is closer to .25 or closer to 0 but one gets some non-trivial updating on priors to this question as a_1 is roughly twice a_3. After all 15% is close to 12.5%. It does reject the notion that s–l is closer to .25 than it is to 0. This also shows how there can be drastically different results in the posterior probabilities depending on the prior probabilities in the case that a likelihood ratio is close to 1.
If I haven’t made a formatting error it will be a figurative miracle.
LikeLike
Benjamin, the comment is readable so I’m leaving it as is. For future reference, the comments use WordPress markup, which you can read about here.
LikeLike
@Benjamin Arthur Schwab:
If I choose priors the way I think you’re describing, I get the same numbers you do. Taking a single representative point from each region does make a substantial difference.
As an example with somewhat similar numbers to that in the post, suppose we observe one sample s of a normally distributed* random variable with unknown mean m and known variance 25. We use a uniform prior since we have no idea what m is, so our posterior for m is normal with mean s and variance 25.
We’ve decided that if m = 25, we want to take action A, and if m = 0 we want to take action B. We can use point estimates to compare the posterior probability density of m = 25 and m = 0:
p(m=25) = exp(-(25-s)^2 /50) / sqrt(50 pi)
p(m=0 ) = exp(-s^2/50) / sqrt(50 pi)
If s = 15, this gives odds of exp(-2) : exp(-4.5), or 12:1, or 92:8 in favor of m = 25.
However, that’s not the right odds for whether m is closer to 25 than to 0. For that, we need to compare the integral of the posterior from 12.5 to infinity with the integral from -infinity to 12.5. That gives odds of 2.2:1, or 69:31, in favor of “closer to 25.” Using the point estimates to approximate these odds would make us substantially overconfident.
For a normal distribution with mean zero, the probability of being closer to some positive number a than to -a-1 equals the probability of being greater than -0.5, which does not depend on a. The point probability densities (with variance 1) are
p(a) = exp(-a^2/2) / sqrt(2 pi)
p(-a-1) = exp(-(a+1)^2/2) / sqrt(2 pi),
with a ratio p(a)/p(-a-1) = exp(a+1/2) that goes to infinity with a. So if we’re unlucky, the point estimate could be arbitrarily overconfident. If the underlying distribution were asymmetric, even the direction might be wrong.
P.S. Thanks Jacob for all your writing.
*The beta/Dirichlet posterior from the post is approximately normal with this many survey answers.
LikeLiked by 2 people
@aiguille
I thank you for your response. It’s nice to know that I did something right.
So in addition to liking this analysis for pointing out a situation in which one’s prior judgment does not have a noticeable impact on ones posterior judgement and a situation in which it does have a noticeable impact, I like this analysis for emphasizing the importance of asking the right specific question and then undertaking a method that specifically answers that specific question.
Problems in probability are so hard in large part because what the right specific question is isn’t always clear. (Well, at the root, probability problems are so hard because Homo Sapien minds aren’t built to handle probability well but are built to be hypergood at finding patterns). I am rarely stumped by the mathematics but I am also rarely completely confident that my approach is the right one. I’m glad to have feedback that I did my analysis correctly (I’ve never did Bayesian analysis in school). I thank you for it.
LikeLike
Even with perfect analysis, I don’t think the question you asked on the survey can actually inform the decision “should I prefer writing long posts to short ones?”. The survey asks “Do you prefer the long posts?”. As a reader who likes your content, if I see a post that is long, I’m more happy because there’s more content. But as for actually writing longer posts I assume there is a trade off where the decision to write longer posts will lead to less posts because of limited time or limited willpower/procrastination. If you included a statement in the survey about the presence or absence of a tradeoff with frequency, it would have been more valid. Or if you had an option for “maximize total content”.
I imagine the actual answers to the survey include people making tons of different assumptions about the presence or absence of any tradeoff. If many people chose longer posts because they just like more content, but if in real life there’s a tradeoff, then you risk interpreting the results wrong.
LikeLiked by 1 person
After a valiant struggle I concluded about halfway through your post that I am just too math-illiterate to be reading it. But I tried really hard, and I enjoy your writing style and obvious passion for math. Keep on!
Kat
http://www.withasideofsarcasm.com
LikeLike
I personally would encourage you to read other posts and look out for posts that don’t get into all of the nitty grity detail. I like how Mr. Falkovich writes a lot of content informed by mathematics that doesn’t have mathematics itself in it. I would also encourage Mr. Falkovich to look into including some sort of show/hide effect into math heavy posts to make it easier for some readers to just see the conclusions.
LikeLiked by 1 person
I definitely will, thank you! My boyfriend loves to poke fun of me for my lack of knowledge in the maths and sciences, and he is unfortunately, completely right. So it’s something I’ve actually been trying to work on improving!
LikeLike
Kat, welcome to Putanumonit! This post is definitely a tough place to start if you don’t already have some math background. I put all posts like this in the “math class” category. The posts in the other categories, even when inspired by a math-nerdy view of the world, don’t require digging through a lot of detailed calculations or equations.
LikeLike
I will definitely check some of them out, thanks!!
LikeLike
I joined the p-values are always bad group a while ago, but have been rethinking it recently. I don’t think I am educated enough in error statistics to prove to myself if they are right/wrong from first principles, but Deborah Mayo views lots of the anti P-value writing as overblown (https://errorstatistics.com/2016/06/08/so-you-banned-p-values-hows-that-working-out-for-you-d-lakens-exposes-the-consequences-of-a-puzzling-ban-on-statistical-inference/).
In that blog post one example is testing for the existence of non-zero amounts of pollution from a random sample of 100 fish from a lake. In that case a null hypothesis of the parameter being zero, and finding the p-value of rejection, could be fine, no? I think it would accurately represent what the truth looks like by showing the probability of rejection based on the sampling distribution.
I think what might be a problem isn’t strictly p-values vs. posterior probabilities, but that analysis that uses a p-value tends to be correlated with a less scientifically sophisticated practitioner. Whereas Bayesian analysis tends to require more thoughtful rigor. It’s pretty easy to run a regression in Stata and report a p-value. As far as I’m aware there is nothing in the Bayesian world half as easy.
LikeLike
In my opinion, I think a lot of this is that p-values are the scientific norm. I think if Bayesian analysis were the scientific norm then there would be tools that would more easily give Bayesian results (in Excell for example) and it would be abused greatly. I think there is value in pointing out bad frequency analysis both from the perspective that Bayesian statistics will give better results (at-least until people become well aware of how to abuse it) and how to make the frequency analysis better. Doing either will improve science.
LikeLike
If all you care about is finding out if the amount of pollution is 0 or “literally any number other than 0” than yes, testing a single hypothesis (“0 or not”) is OK. If there’s some tiny non-zero amount of pollution that you would treat as if it were zero, you will still do better by having at least one alternative hypothesis which is the minimum “treatment-requiring” pollution amount. Doing a likelihood ratio for two discrete alternatives is really just as easy as calculating a p-value, you do it in Excel with the same NORM.DIST function.
If an MBA can do some simple Bayes, so can a social science PhD ;)
But really, how easy it is to do something shouldn’t be our first criterion. If you could bang out good science using either approach, you can go with the easier one. But if a discipline (i.e. psychology) is mired in a replication crisis that casts real doubt on the veracity of almost everything published in it, the focus should be on finding approaches that actually work before worrying about how easy they are.
LikeLike
Are there any actual frequentist statisticians, who are aware of Baysianism but are against it? Or is it like Newtonian vs. Relativistic Gravity, where everyone knows which one is more accurate but people neglect it because it’s computationally harder?
LikeLike
Null hypothesis statistical testing is genuinely terrible. You can’t find anyone competent defending it and I don’t think you can find anyone incompetent to defend it, either, beyond it being the entrenched standard. But identifying NHST with frequentism is an error. Simply switching to confidence intervals addresses almost every complaint Jacob makes. And yet confidence intervals are just another representation of p-values.
It is certainly true that even sophisticated frequentists are barely aware of bayesianism. Probably the most prominent actual critic of bayesianism is Deborah Mayo, cited by Natasha, above. But flip the question around: are you aware of frequentism? Do you even know what a p-value is? Here’s a quantitative measure: how many errors about p-values did you spot in this post?
LikeLike
The part about p-values and statistical significance reminds me of a paper of ours about prediction markets — http://messymatters.com/prediction-without-markets/ — in which we concluded that markets perform statistically significantly better than other forecasting methods but are otherwise insignificantly better. In that blog post we made up the term “gold medal syndrome” to describe the obsession with statistical significance without regard to actual significance.
LikeLike
Whoa, I didn’t know you were authoring research papers. I read the paper itself, it’s fascinating and remarkably well written.
I’d love to chat with you about that paper some time, but for now I have one question that immediately came to mind: how did you choose the prediction models for football games and movies? Why the results of the last 16 games, and not points scored? Why Google searches and not MetaCritic rating? If these models were picked at random, that’s really impressive. If these are the absolute best 2-3 parameter models out of all the thousands that could have been tried (garden of forking paths alert), then the fact that prediction markets outperform them at all is a point in favor of prediction markets.
LikeLiked by 1 person
Thanks! Sounds like we should’ve emphasized that, yes, we picked those models at random. That would be super unfair to search for good models! :) The idea was to show that prediction markets aren’t a magic crystal ball and, indeed, it seems that the most simplistic possible models tend to be virtually as accurate. Asking a single person, expert or not, to predict something is still much worse. :)
LikeLiked by 1 person
I might be nitpicking some but I am under the impression that you like being nitpicked.
1: In the third paragraph the link to “greatness-enhancing feedback” goes to the subscription page. I wanted to look at the actual questions from the survey for an above comment and the link I thought would get me there didn’t.
2:
Isn’t a third possibility to get statistics that could be used for a variety of reasons some of which aren’t known at the time of the analysis. I’ve made use of census department statistics for reasons different the others use the same statistics for. We’re both making decisions but the decisions are different. This is a non-trivial reason to do data analysis and the result is an accurate picture with appropriate uncertainties given and would yield a different data analysis then the other two.
The point that the goal of getting published in an academic journal does not always lead to an increase in true information is well taken.
3:
In my physics education this is what we were taught to do. We would, say, if the Hall effect does not exist then we should get values within a certain range when we take this measurement in this experimental set up. We do the experiment then we calculate the probability that given the Hall effect not existing, the chances that our experiment would give values more outside this range then we got. If these probabilities are consistently low then this gives a high chance that the Hall effect exists. There can be more information gathered in an experiment sure. In this example, which side of the range the measurements are on lets one know whether electrons are positive or negative. In other cases a particular value as well as the uncertainty in this value can be measured. The Hall effect not existing was called the “null hypothesis,” in this example.
4:
5:
LikeLike
There is another, simpler model of statistical testing, for which (I believe) frequentist statistics is entirely appropriate, and which doesn’t have an obvious place for a Bayesian prior.
What I am working on is measuring the market value of pension liabilities sponsored by corporations. I am going about this by setting up a linear regression, where the dependent variable is a function of market capitalization (i.e., the value of the company’s stock). Because pensions are a liability embedded within the company, using regression seems like the most straightforward way to measure them.
One of the terms in the regression relates to the pension plan (zero if the company does not have a pension plan). I seek to estimate this coefficient, and use this to estimate the market value of pension liabilities.
I would describe this model as one-dimensional, whereas a typical attack on frequentist statistics is based on a two-dimensional set-up involving a test, and the power of the test is important.
LikeLike
A prior is like dessert, there’s always room for it :)
Your prior should be some distribution of possible values this coefficient can take. Can it be negative? Is it equally likely to be 0.0001 or 10,000? You usually know something about it.
If you’re going to roll with the regression estimate no matter what, it’s the same as using a non-informative prior which makes the posterior depend only on the likelihood function given by the data. And if that’s the case then you’re really not using the prior for anything so you may as well save the hassle and go without it.
Two reasons why you may still want to do Bayesian inference:
LikeLike
If you are seeking to estimate the value of a regression coefficient, I think it is fair game to use as a Bayesian prior a value or range of some other variable which is somehow related. But, to assign (as a prior) a value or range to the very coefficient that you are estimating is just circular reasoning. I don’t believe that circular reasoning is ever helpful.
LikeLike
A prior tells you where started from, the evidence tells you which direction and how far to go. If you know both, you know where you should end up. It’s sequential logic (prior -> evidence -> posterior -> new evidence -> new posterior), the opposite of circular.
Deciding that you’re going to arrive at whichever point estimate the regression gave you just means you had an implicit prior, for example a uniform distribution. Narrowing down where you start from helps you be more accurate regarding where you end up, it doesn’t mean that you’re going in circles.
LikeLike
Good article, Jacob. A thorough account of why the “p-value school” results in people performing an activity that is barely even science. I will save this article to my documents and maybe share it with some friends. This post’s quality is also an indication that I should read through your blog history — as if I didn’t have enough Internet people to read!
LikeLike