I’m back from vacation! Here are some of the things we did abroad:
- Ate too much octopus. Or is it “too many octopods”?
- Bribed a cop.
- Watched quail chicks hatch.
- Got locked in an apartment and escaped by climbing from roof to roof.
- Poked a sea turtle.
- Endured getting stung by mosquitoes, jellyfish and fire coral.
- Swam in the sea. Swam in a cave. Swam in a river. Swam in a cave-river flowing into the sea.
- Snuck into a defunct monkey sanctuary whose owner was killed by a runaway camel and which is now haunted by mules and iguanas.

I returned from the wilderness tanner, leaner, and ready to expound about proper epistemology in science. This is going to get really technical, I need to get my math-cred back after writing 5,000 words on feminism, Nice Guys and living with my ex-girlfriend.
Effect-skeptic, not Ovulation-skeptic
This post is about gauging the power of experiments in science. I originally presented this to a group of psychology grad students, as advice on how to avoid publishing overconfident research that will fail to replicate (I’ve never actually published a scientific article myself, but neither was I ever accused of excess humility). This subject is just as relevant to people who read about science: quickly estimating the power of an experiment you read about can give you a strong hint whether it’s a groundbreaking discovery or a p-hacked turd sandwich. Like other tools in the Putanumonit arsenal of bullshit-detectors, this is tagged defense against the dark arts.
I was inspired by Prof. Uri Simonsohn, data vigilante and tireless crusader against the dark arts of fake data, misleading analysis and crappy science. Simonsohn recently appeared on Julia Galef’s Rationally Speaking podcast and had a very interesting take on science skepticism:
Some people would say you really have to bring in your priors about a phenomenon before accepting it. I think the risk with that is that you end up being too skeptical of the most interesting work, and so you end up, in a way, creating an incentive to doing obvious and boring research.
I have a bit of a twist on that. I think we should bring in the priors and our general understanding and skepticism towards developing the methodology, almost blind to the question or the hypothesis that’s being used.
Let’s say you tell me you ran an experiment about how preferences for political candidates shift. Then I should bring to the table how easy it is to shift political preference in general, how noisy those measures are and so on, and not put too much weight on how crazy I think it is that you tell me you’re changing everything by showing an apple below awareness. My intuition on how big the impact of apples below awareness are in people is not a very scientific prior. It’s a gut feeling.
I don’t know that the distinction is clear, but when it’s my prior about the specific intervention you’re claiming, there I try not to trust my intuition. And the other one is, what do I know about the reliability of the measures, how easy it is to move the independent variable? There I do, because in the latter case it’s based on data andthe other one is just my gut feeling.
Here’s how I understand it: when you read a study that says “A causes B as measured by the Tool of Measuring B (ToMB)” you usually know more about B (which is some variable of general interest) and the accuracy of ToMB than you know about A (which is usually something the study’s authors are experts on). Your skepticism should be based on these two questions:
- How easy it is to move variable B and by how much?
- Is the sample size large enough to measure the effect with ToMB?
You should not be asking yourself:
- How likely was A to cause the effect?
Because you don’t know. If everyone had a good idea of what A does, scientists wouldn’t be researching it.
As Simonsohn alludes to, political-choice research is notorious for preposterous effect size claims. Exhibit A is the unfortunate “The fluctuating female vote: politics, religion, and the ovulatory cycle” which claims that 17% of married women shifted from Obama to Romney during ovulation. This should smell like bullshit not because of the proposed cause (ovulation) but because of the proposed effect (voting switch): shifting even 1% of voters to the opposite party is insanely hard. Reason doesn’t do it. Self-interest doesn’t do it. I suspect that we would notice if 10 million women changed their political affiliation twice a month.

Finding an effect that large doesn’t mean that the experiment overstated a small effect, it means that the experiment is complete garbage. +17% is basically as far away from +1% as it is from -1% (effect in the opposite direction). An effect that’s 20 times larger than any comparable intervention doesn’t tell you anything except to ignore the study.
Per Simonsohn, the ovulation part should not be a reason to be doubtful of the particular study. After all, the two lead authors on “fluctuating” (both women) certainly know more about ovulation that I do. In fact, the only thing I know of that correlates highly with ovulation is the publishing of questionable research papers.
Stress Testing
For scientists, the time to assess the possible effect sizes is before the experiment is conducted, not afterwards. If the ovulation researchers predicted an effect of +0.5% before doing the study, the +17% result would’ve alerted them that something went wrong and spared them from embarrassment when the study was published and when it was (predictably) contradicted by replications.
Estimating the effect size can also alert the researchers that their experiment isn’t strong enough to detect the effect even if it’s real, that they need to increase the sample size or design more accurate measurements. This could’ve prevented another famous fiasco in psychology research: the power pose.

“Power posing” is the subject of the second most popular TED talk of all time. I got the link to it from my ex-girlfriend who eagerly told me that watching it would change my life. I watched it (so you shouldn’t). I read the original paper by Carney, Cuddy and Yap (CC&Y). I offered to bet my ex-girlfriend $100 that it wouldn’t replicate. Spoiler alert: it didn’t, and I am currently dating someone with superior scientific skepticism skills.

Let’s see how predictable the powerlessness of power posing was ahead of time. CC&Y claim that holding an expansive “power” pose not only increases self-reported “feeling of power” but also affected lowered levels of cortisol – a hormone that is released in the body in response to stress and affects functioning.
We want to find out how cortisol fluctuates throughout the day (which would affect measurement error) and how it responds to interventions (to estimate effect size). A quick scholar-Googling leads us to a 1970 paper on the circadian cortisol pattern in normal people. It looks like this:

Cortisol levels vary daily over the range between 5 and 25 µg/dl (shown on the chart as 0-20). Daily mean cortisol levels vary by about 4 µg/dl person-to-person (that’s the standard deviation) and measurements 20 minutes apart for the same person vary by about 2.5 µg/dl. There’s also an instrument error (how accurately taking a saliva sample measures actual cortisol levels) which is too annoying to google. Since CC&Y measure the difference in cortisol levels between two groups of 21 people 17 minutes apart, their standard error of measurement should be around:

Ideally, to measure the effect of anything on cortisol that effect should be at least 3 times the measurement error, or around 3.6. A source for possible effect size estimates is this work on caffeine, stress and cortisol by Lovallo 2008.

The caffeine paper uses a slightly different measurement of cortisol but we can superimpose the 1-5 range in the chart on the normal daily 5-25 µg/dl level. Best I could tell, drinking a ton of coffee affect cortisol levels by 4 µg/dl. More interestingly, the subjects in Lovallo’s study underwent a “stress challenge” at 10 am specifically designed to raise their cortisol. Which it did, by around 2 µg/dl. I may be willing to accept that 1 minute of posing has half the effect of a 30 minute stress challenge on stress hormones, but no more. That means that by having only 42 participantsCC&Y are looking for a 1 µg/dl effect in a measurement with 1.2 µg/dl error. These numbers mean that the experiment has 13% power (I’m perhaps too generous) to detect the effect even at the weak p=0.05 level. The experiment has a 20% chance to find an effect with the opposite sign (that power poses raise cortisol instead of reducing it) even if CC&Y’s hypothesis is true.
Unless something is inherently broken with the measurement methodology, the straightforward solution to increase experimental power is to increase the sample size. How much does it cost to pay an undergrad to spend 20 minutes in the lab and spit in a tube? A cynic would say that the small sample size was designed to stumble upon weird results. I don’t know if I’m that cynical, but the replication recruited 200 subjects and found that the effect on cortisol is as follows:

When an underpowered experiment finds a significant effect, it’s rarely because the scientists got lucky. Usually, it’s because the experiment and analysis were twisted enough to measure some bias or noise as a significant effect. It’s worse than useless.
Too Late for Humility
There’s nothing wrong with running an underpowered experiment as exploratory research – a way of discovering fruitful avenues of research rather than establishing concrete truths. Unfortunately, my friends who actually publish papers in psychology tell me that every grant request has “power = 80%” written in it somewhere, otherwise the research doesn’t get funded at all. A scientist could expend the effort of calculating the real experimental power (13% is a wild guess, but it’s almost certainly below 20% in this case), even if that number is to be kept in a locked drawer. If she does, she’ll be skeptical enough not to trust results that are too good to be true.
Here’s a beautiful story of two scientists who got a result that seemed a tad too good for the quality of their experimental set-up. They stayed skeptical, ran a replication with pre-planned analysis (the effect promptly disappeared) and spun the entire ordeal into a publication on incentive structures for good science practices! Here’s the under appreciated key part in their story:
We conducted a direct replication while we prepared the manuscript.
Humility and skepticism have a chance to save your soul (and academic reputation), but only until you are published. Perhaps Carney and Cuddy would’ve agreed with my analysis of the 13% power, but there’s no sign that they did the calculation themselves. Even if they originally wrote “80%” just as a formality to get funded, once they neglected to put a real number on it nothing will keep them from believing that 80% is true. Confirmation bias is an insidious parasite, and Amy Cuddy got the TED talk and a book deal out of it even as all serious psychologists rushed to dismiss her findings. As the wise man said: “It is difficult to get a man to understand something, when his salary depends on his not understanding it. ”

In her TED talk, Cuddy promises that power posing has the power to change anyone’s life. In a journal reply to the replication by Ranehill, she’s reduced to pleading that power posing may work for Americans but not Swiss students, or that it worked in 2008 but not in 2015, or seriously arguing that it only works for people who have never heard of power posing previously, making the TED talk self-destructive. If you’re left wondering how Carney, Cuddy and Yap got the spurious results in the first place, they oblige to confess it themselves:
Ranehill et al.used experimenters blind to the hypothesis, and we did not. This is a critical variable to explore given the impact of experimenter bias and the pervasiveness of expectancy effects.
Let me translate what they’re saying:
We know that non-blind experiments introduce bogus effects, that our small-sample non-blind experiment found an effect but a large-sample blind study didn’t, but yet we refuse to consider the possibility that our study was wrong because we’re confirmation biased like hell and too busy stackin’ dem benjamins.
Questioning Love and Science
Let’s wrap up with a more optimistic example of using power-estimation to inform us as readers of research, not scientists. At the end of Love and Nice Guys I mentioned the article on the 36 questions that create intimacy, itself based on this research by Arthur Aron et al. Again, we withhold judgment on the strength of the intervention (the 36 questions) and focus on the effect, in this case as measured by the corny-sounding Inclusion of Other in the Self Scale (IOS).
A search of interventions measured by IOS leads us to the aptly-titled “Measuring the Closeness of Relationships” by Gachter et al. which includes the following table:
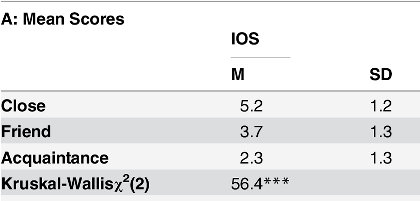
The IOS measures an equal difference (1.4-1.5) between good friends and either the “closest, deepest, most involved, and most intimate relationship” or on the other hand an “acquaintance, but no more than an acquaintance”. The SD of the scale is 1.3, and since Aron has 50 people in each group (36 questions vs. just small talk) we divide 1.3 by the square root of 50 to get a standard error of 0.18. To achieve 80% power at p=0.05 (80% at .05 should be the bare minimum standard) the effect of an hour discussing the 36 questions should be 0.5, or roughly one third of the distance between acquaintances and friends. (Here’s a power-calculator, I just use Excel).
An intimate hour taking people one third of the way to friendship doesn’t seem implausible, and in fact the study finds that the intimacy-generating 36 questions increase IOS by 0.88: high enough to be detectable, low enough to be plausible. We don’t know if the IOS is really a great measure of intimacy and potential for love, but that’s outside the scope of the study. They found the effect that was there, and I expect these findings to replicate when people try to confirm them. Putanumonit endorses asking potential partners “how do you feel about your relationship with your mother?” (question 24) as trustworthy science. The whole of the googling and power-calculating took me just under half an hour.

I’m not this energetically skeptical about every piece of science news I hear about, but I am more likely to be suspicious of research that pops up on my Facebook wall. If you read about a new study in the NY Times or IFLScience, remember that it’s covered because it’s exciting. It’s exciting because it’s new and controversial, and if it’s new and controversial it’s much more likely than other research to be flat out wrong. If you think of power-posing every day or planning to seduce the man of your dreams with questions, 30 minutes of constructive skepticism can keep you out of the worst trouble.

That was spectacular! This post should be required reading in college, regardless of major. And to be sure that the message gets across properly, the reading should be repeated every semester (perhaps with a new example of a big scandal each time).
LikeLike
I really loved this one!
Investigating the measurement of the affected variable and how hard it is to change it, instead of judging the intervention beforehand, is definitely something I’m going to keep in mind.
“Ideally, to measure the effect of anything on cortisol that effect should be at least 3 times the measurement error, or around 3.6. ”
Where does the 3 come from? Is it a convention?
Typos:
“A scientist could spend the effort to calculate the real experimental power (13% is a wild guess, but it’s almost certainly below 20% in this case), that number to be kept in a secret locked drawer.” Missing word?
“We don’t if the IOS is really a great measure of intimacy and potential for love, but that’s outside the scope of the study”
We don’t know…
LikeLike
Glad you loved it, typos are fixed, thanks!
Assuming normal assumptions, an effect that’s 3 times larger than the SE is what gets you to 80% power at the 0.05 level. In a bit more detail: if the null hypothesis is that the effect is 0, you need to measure an effect above 1.96 SDs to reject the null at 0.05. If the true mean of the effect is 3 SDs, you have an 80% chance of measuring 1.96 or above.
In all honesty, I believe that thinking in terms of p-values (especially the silly p=0.05 cutoff) is in itself counterproductive to good science (more posts on that later). However, doing power calculations at least makes you predict the effect rather than just predicting that the null will be rejected. That gives you an actual hypothesis to actually compare the data to which makes you a lot smarter even if you’re not explicitly Bayesian.
For example, if the Romneyvulation researchers predicted an effect of 2% when calculating power, they would’ve known that a measured effect of 17% means that the experiment is broken. Similarly, in the Lukewarm Hand post I mentioned the study where the authors compared the result (4% shooting gap) to the null (0%) but not to the alternative hypothesis of 8% which fit the data just as well as 0%. By ignoring everything except for the null, they arrived at the wrong conclusion.
LikeLike
Ah, so it’s related to the 80% power convention?
Looking forward to the later posts!
LikeLike
Comment #1: If you want to act in accordance with trustworthy science and you want an intimate relationship with your readers (I don’t actually know if this is a goal of yours), should you answer those 36 questions for us? ;-)
Comment #2: Now I’m waiting for a paper that claims something like: “This activity decreases cortisol levels 150%.”
LikeLike
Re #1: I love and admire my mom very much. Especially since she reads this blog.
Re #2: With enough bad methodology and a small sample size, I can convince you that reading this blog always makes your cortisol land on a number divisible by 3.
LikeLike
Edifying! Thank you! Are you still procrastinating on that procrastination post? :)
LikeLike
I am, I don’t seem to get around to writing it without a Beeminder track ;)
My next post isn’t going to be on procrastination either, it’s about a chance for me and my readers to change the world for the better. Stay tuned!
LikeLike
What do I need to read in order to understand “power of experiment”, why you calculate standard deviation for all those samples and how to spend half an hour to calculate such things for a paper?
Also I wonder, how many other articles, papers, etc. have you read and decided that they either would replicate or would not replicate, and about how many of them were you right?
LikeLike
Also do I understand correctly, that p-value = 1/20 means that the researchers think that given null hypothesis and some assumptions (for example an assumption that some variable distribution is gaussian), the probability to get such experimental data or more extreme experimental data is less or equal than 1/20?
If this is true, do researchers decide how to measure extremeness of data before doing the experiment?
LikeLike
For measuring a single number (i.e. the effect in ug/dl of power posing on cortisol) scientists usually take an optimistic estimate of the standard error for a single person, divide that by the square root of the sample size to get the SD of the entire sample, and if the average effect (after throwing out outliers they don’t like) is at least 1.96 as large as the sample SD a normal distribution gives you a p-value of 0.05. There are always many choices to make even if the basic procedure is standard, so it’s always a good idea to not just decide on the exact analysis ahead of time but also tell other people (preregister) so they can hold you accountable.
If you want a better overview of the math, google “hypothesis testing” and “statistical power” along with words like “explained” or “introduction”. I don’t go into too much detail on purpose: this material is easily available and my readers have wildly varying background knowledge. If I tried to write a statistics textbook myself in every post half the people still won’t understand it and half will be bored and leave, any explanation of a given length is aimed at a very thin slice of people. Some brilliant people are building a website to solve that problem and customize an explanation for each reader.
I probably read about a paper per week, mostly when I see popular stories about them shared on social media and they smell fishy. That was my point in the last paragraph: the research you are most likely to read about (because it’s exciting and controversial) is the research most likely to be bunk.
LikeLike