P-Vices
Of all the terrible vices known to man, I guess NFL gambling and alternative medicine aren’t very terrible. Making medicine that doesn’t work (if it worked, it wouldn’t be alternative) is also a tough way to make money. But if you’re able to squeeze a p-value of 0.05 for acupuncture out of a trial that clearly shows that acupuncture has zero effect, you can make money and get a PhD in medicine!
It’s also hard to make money off of gambling on the NFL. However, you can make money by selling NFL gambling advice. For example, before the Eagles played as 6 point underdogs on the turf in Seattle after a 208 yard rushing game, gambling guru Vince Akins declared:
The Eagles are 10-0 against the spread since Dec 18, 2005 as an underdog and on turf after they’ve had more than 150 yards rushing last game.
10-0! Betting against the spread is a 50-50 proposition, so 10-0 has a p-value of 1/(2^10) = 1/1024 = 0.0009. That’s enough statistical significance not just to bet your house on the Eagles, but also to get a PhD in social psychology.
The easiest way to generate the p-value of your heart’s desire it to test multiple hypotheses, and only report the one with the best p-value. This is a serious enough problem when it happens accidentally to honest and well-meaning researchers to invalidate whole fields of research. But unscrupulous swindlers do it on purpose and get away it, because their audience suffers from two cognitive biases:
- Conjunction fallacy.
- Sucking at statistics.
No more! In this new installment of defense against the dark arts we will learn to quickly analyze multiplicity, notice conjunctions, and bet against the Eagles.
Hacking in Depth
[This part gets stats-heavy enough to earn this post the Math Class tag. If you want to skip the textbooky bits and get down to gambling tips, scroll down to “Reading the Fish”]
The easiest way to generate multiple hypotheses out of a single data set (that didn’t show what you wanted it to show) is to break the data into subgroups. You can break the population into many groups at once (Green Jelly Bean method), or in consecutive stages (Elderly Hispanic Woman method).
The latter method works like this: let’s say that you have a group of people (for example, Tajiks) who suffer from a medical condition (for example, descolada). Normally, exactly one half of sick people recover. You invented a miracle drug that takes that number all the way up to… 50%. That’s not good enough even for the British Journal of General Practice.
But then you notice that of the men who took the drug 49% recovered, and of the women, 51% did. And if you only look at women above age 60, by pure chance, that number is 55%. And maybe 13 of these older Tajik women, because Tajikistan didn’t build a wall, happened to be Hispanic. And of those, by accident of random distribution, 10 happened to recover. Hey, 10 out of 13 is a 77% success rate, and more importantly it gives a p-value of… 0.046! Eureka, your medical career is saved with the publication of “Miracle Drug Cures Descolada in Elderly Hispanic Women” and you get a book deal.
Hopefully my readers’ nose is sharp enough not to fall for 10/13 elderly Hispanic women. Your first guide should be the following simple rule:
Rule of small sample sizes – If the sample size is too small, any result is almost certainly just mining noise.
Corollary – If the sample size of a study is outnumbered 100:1 by the number of people who died because of that study, it’s probably not a great study.
But what if the drug did nothing detectable for most of the population, but cured 61 of 90 Hispanic women of all ages. That’s more than two thirds, the sample size of 90 isn’t tiny, and it comes out to a p-value of 0.0005, is that good enough?
Let’s do the math.
First, some theory. P-values are generally a terrible tool. Testing with a p-value threshold of 0.05 should mean that you accept a false result by accident only 5% of the time, yet even in theory using a 5% p-value makes a fool of you over 30% of the time. P-values do one cool thing, however: they transform any distribution into a uniform distribution. For example, most samples from a normal distribution will lie close to the mean, but their p-values will be spread evenly (uniformly) across the range between 0 and 1.
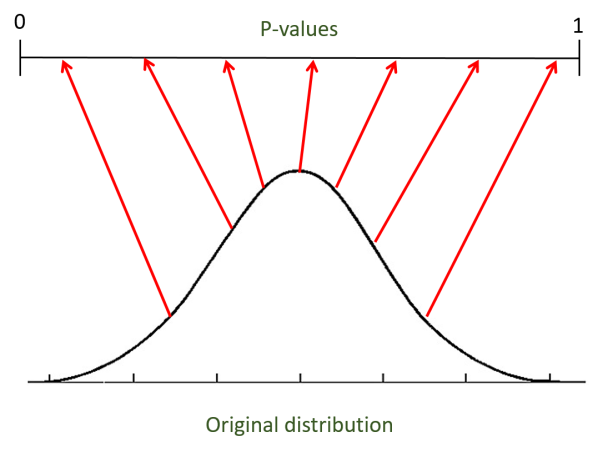
Uniform distributions are easy to deal with. For example, if we take N samples from a uniform distribution and arrange them by order, they will fall on average on 1/N+1, 2/N+1, .. N/N+1. If you test four hypotheses (e.g. that four kinds of jelly beans cause acne) and their p-values fall roughly on 1/(4+1) = 0.2, 0.4, 0.6, 0.8 you know that they’re all indistinguishable from the null hypothesis as a group.
Usually you would only see the p-value of the best hypothesis reported, i.e. “Wonder drug cures descolada in elderly Hispanic women with p=0.0005”. The first step towards sanity is to apply the Bonferroni rule:
Bonferroni Rule – A p-value of α for a single hypothesis is worth about as much as a p-value of α/N for the best of N hypotheses.
The Bonferroni correction is usually given as an upper bound, namely that if you use an α/N p-value threshold for N hypotheses you will accept a null hypothesis as true no more often than if you use an α threshold for a single hypothesis. It actually works well as an approximation too, allowing us to replace no more often with about as often. I haven’t seen this math spelled out in the first 5 google hits, so I’ll have to do it myself.
h1,…,hN are N p-values for N independent tests of null hypotheses. h1,…,hN are all uniformly distributed between 0 and 1.
The chance that one of the N p-values falls below α/N = P(min(h1,…,hN) < α/N) = 1 – (1 – α/N)N ≈ 1 – e-α ≈ 1 – (1-α) = α = the chance that single p-value falls below α. The last bit of math there depends on a linear approximation of ex =1+x when x is close to 0.
The Bonferroni Rule applies directly when the tests are independent, but that is not the case with the Elderly Hispanic Woman method. The “cure” rate of white men is correlated positively with the rate for all white people (a broader category) and with young white men (a narrower subgroup). Is the rule still good for EHW hacking? I programmed my own simulated unscrupulous researcher to find out, here’s the code on GitHub.
My simulation included Tajiks of three age groups (young, adult, old), two genders (the Tajiks are lagging behind on respecting genderqueers) and four races (but they’re great with racial diversity). Each of the 2*3*4=24 subgroups has 500 Tajiks in it, for a total population of 12,000. Descolada has a 50% mortality rate, so 6,000 / 12,000 cured is the average “null” result we would expect if the drug didn’t work at all. For the entire population, we would get p=0.05 if only 90 extra people were cured (6,090/12,000) for a success rate of 50.75%. A meager success rate of 51.5% takes the p-value all the way down to 0.0005.
Rule of large sample sizes – With a large sample size, statistical significance doesn’t equal actual significance. With a large enough sample you can get tiny p-values with miniscule effect sizes.
Corollary – If p-values are useless for small sample sizes, and they’re useless for large sample sizes, maybe WE SHOULD STOP USING FUCKING P-VALUES FOR HYPOTHESIS TESTING. Just compare the measured effect size to the predicted effect size, and use Bayes’ rule to update the likelihood of your prediction being correct.
P-values aren’t very useful in getting close to the truth, but they’re everywhere, they’re easy to work with and they’re moderately useful for getting away from bullshit. Since the latter is our goal in this essay we’ll stick with looking at p-values for now.
Back to Tajikistan. I simulated the entire population 1,000 times for each of three drugs: a useless one with a 50% success rate (null drug), a statistically significant one with 50.75% (good drug) and a doubly significant drug with 51.5% (awesome drug). Yes, our standards for awesomeness in medicine aren’t very high. I looked at the p-value of each possible sub-group of the population to pick the best one, that’s the p-hacking part.
Below is a sample of the output:
13 hispanic 1 0.122530416511473
14 female hispanic 2 0.180797304026783
15 young hispanic 2 0.25172233581543
16 young female hispanic 3 0.171875
17 white 1 0.0462304905364621
18 female white 2 0.572232224047184
19 young white 2 0.25172233581543
20 young female white 3 0.9453125
21 adult 1 0.368777154492162
22 female adult 2 0.785204746078306
23 asian 1 0.953769509463538
24 female asian 2 0.819202695973217
The second integer is the number of categories applied to the sub-group (so “asian” = 1, “asian adult female” = 3). It’s the “depth” of the hacking. In our case there are 60 groups to choose from: 1 with depth 0 (the entire population), 9 with depth 1, 26 with depth 2, 24 with depth 3. Since we’re testing the 60 groups as 60 separate hypotheses, by the Bonferroni Rule the 0.05 p-value should be replaced with 0.05 / 60 categories = 0.00083.
In each of the 1,000 simulations, I picked the group with the smallest p-value and plotted it along with the “hacking depth” that achieved it. The vertical lines are at p=0.05 p=0.00083. The horizontal axis the hacked p-value on a log scale and the vertical how many of the 1,000 simulations landed below it:
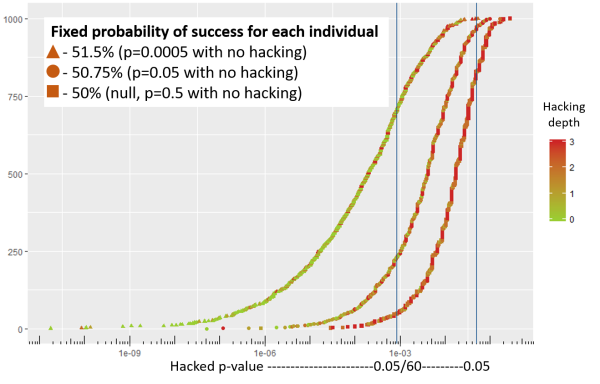
For the null drug, p-hacking achieves a “publishable” p-value of
If your goal is to do actual science (as opposed to getting published in Science), you want to be comparing the evidence for competing hypotheses, not just looking if the null hypothesis is rejected. The null hypothesis is that we have a 50% null drug, and the competing hypothesis are the good and awesome drugs at 50.75% and 51.5% success rates, respectively.
Without p-hacking, the null drug will hit below p=0.05 5% of the time (duh), the good drug will get there 50% of the time, and the awesome drug 95% of the time. To a Bayesian, getting a p-value below 0.05 is a very strong signal that we have a useful drug on our hands: 50%:5% = 10:1 likelihood ratio that it’s the good drug and 95%:5% = 19:1 that it’s the awesome drug. If ahead of time we thought that each of the cases is equally likely (1:1:1) ratio, our ratios would now be 1:10:19, this means that the probability that the drug is the null one went from 1/3 to 1/(1+10+19) = 1/30. The null drug is 10 times less likely.
If you’re utterly confused by the preceding paragraph, you can read up on Bayes’ rule and likelihood ratio on Arbital, or just trust me that without p-hacking, getting a p-value below 0.05 is a strong signal that the drug is useful.
With p-hacking, however, the good and the awesome drugs don’t do so well. We’re now looking how often each drug falls below the Bonferroni Rule line of p=0.00083. Instead of 50% and 95% of the time, the good and awesome drugs get there 23% and 72% of the time. If we started from 1:1:1 odds, the new odds are roughly 1:5:15, and the probability that the drug is the null one is 1/21 instead of 1/30. The null drug is only 7 times less likely.
Rule of hacking skepticism – Even though a frequentist is happy with a corrected p-value, a Bayesian knows better. P-hacking helps a bad (null) drug more than it does a good one (which is significant without hacking). Thus, hitting even a corrected p-value threshold is weaker evidence against the null hypothesis.
You can see it in the chart above: for every given p-value (vertical line) the better drugs have more green points in its vicinity (indicating less depth of hacking) and the bad drug has more red because it has to dig down to a narrow subgroup to luck into significance.
Just for fun, I ran another simulation in which instead of holding the success probability for each patient constant, I fixed the total proportion of cures for each drug. So in the rightmost line (null drug) exactly 6,000 of the 12,000 were cured, for the good drug exactly 6,090 and for the awesome drug 6,180.

We can see more separation in this case – since the awesome drug is at p=0.0005 for the entire group, hacking can not make it any worse (that’s where the tall green line is). Because for each drug the total cures are fixed, if one subgroup has more successes the other one by necessity have less. This mitigates the effects of p-hacking somewhat, but the null drug still gets to very low p-values some of the time.
Reading the Fish
So what does this all mean? Let’s use the rules we came up with to create a quick manual for interpreting fishy statistics.
- Check the power – If the result is based has a tiny sample size (especially with a noisy measure) disregard it and send an angry email to the author.
- Count the categories – If the result presented is for a subgroup of the total population tested (i.e. only green beans, only señoritas) you should count N – the total number of subgroups that could have been reported. Jelly beans come in 50 flavors, gender/age/race combine in 60 subgroups, etc.
- Apply the correction – divide the original threshold p-value by the N you calculate above. If the result is in that range, it’s statistically significant.
- Stay skeptical – Remember that a p-hacked result isn’t as good of a signal even with correction, and that statistical significance doesn’t imply actual significance. Even an infinitesimal p-value doesn’t imply with certainty that the result is meaningful, per the Rule of Psi.
Rule of Psi – A study of parapsychological ability to predict the future produced a p-value of 0.00000000012. That number is only meaningful if you have absolute confidence that the study was perfect, otherwise you need to consider your confidence outside the result itself. If you think that for example there’s an ε chance that the result is completely fake, that ε is roughly the floor on p-values you should consider.
For example, if I think that at least 1 in 1,000 psychology studies have a fatal experimental flaw or are just completely fabricated, I would give any p-value below 1/1,000 about as much weight as 1/1,000. So there’s a 1.2*10^-10 chance that the parapsychology meta-analysis mentioned above was perfect and got a false positive result by chance, but at least 1 in 1,000 chance that one of the studies in it was bogus enough to make the result invalid.
Let’s apply our manual to the Eagles game:
The Eagles are 10-0 against the spread since Dec 18, 2005 as an underdog and on turf after they’ve had more than 150 yards rushing last game.
First of all, if someone tells you about a 10-0 streak you can assume that the actual streak is 10-1. If the Eagles had won the 11th game going back, the author would have surely said that the streak was 11-0!
The sample size of 11 is really small, but on the other hand in this specific case the error of the measure is 0 – we know perfectly well if the Eagles won or lost against the spread. This doesn’t happen in real life research, but when the error is 0 the experimental power is perfect and a small sample size doesn’t bother us.
What bother us is the insane number of possible variables the author could have mentioned. Instead of [Eagles / underdog / turf / after 150 yards rushing], the game could be described as [Seattle / at home / after road win / against team below average in passing] or [NFC East team / traveling west / against a team with a winning record] or [Team coming off home win / afternoon time slot / clear weather / opponent ranked top-5 in defense]. It’s hard to even count the possibilities, we can try putting them in separate bins and multiplying:
- Descriptors of home team – division, geography, record, result of previous game, passing/rushing/turnovers in previous game, any of the many season stats and rankings – at least 20
- Descriptors of road team – at least 20
- Game circumstances – weather, time slot, week of season, field condition, spread, travel, matchup history etc. – at least 10.
Even if you pick just 1 descriptor in each category, this allows you to “test” more than 20*20*10 = 4,000 hypotheses. What does it mean for the Eagles? A 10-1 streak has a p-value of 0.0107, about 1/93. But we had 4,000 potential hypotheses! 1/93 is terrible compared to the p=1/4,000 we would have expected to see by chance alone.
Of course, this means that the gambling guru didn’t even bother testing all the options, he did just enough fishing to get a publishable number and published it. But with so much potential hacking, 10-1 is as much evidence against the Eagles as it is in their favor. The Eagles, a 6 point underdog, got their asses kicked by 11 points in Seattle.

You can apply the category-counting method whenever the data you’re seeing seems a bit too selected. The ad above tells you that Trinity is highly ranked in “faculties combining research and instruction”. This narrow phrasing should immediately make you think of the dozens of other specialized categories in which Trinity College isn’t ranked anywhere near the top. A college ranked #1 overall is a great college. A college ranked #1 in an overly specific category within an overly specific region is great at fishing.
To No And
It’s bad enough when people don’t notice that they’re being bamboozled by hacking, but digging deep to dredge up a narrow (and meaningless) result can sound more persuasive than a general result. Here’s an absolutely delightful example, from Bill Simmons’ NFL gambling podcast:
Joe House: I’m taking Denver. There’s one angle that I like. I like an angle.
Bill: I’m waiting.
Joe House: Defending Super Bowl champions, like the Denver Broncos, 24-2 against the spread since 1981 if they are on the road after a loss and matched up against a team that the previous week won both straight up and against the spread and the Super Bowl champion is not getting 7 or more points. This all applies to the Denver Broncos here, a wonderful nugget from my friend Big Al McMordie.
Bill: *sigh* Oh my God.
I’ve lost count of how many categories it took House to get to a 24-2 (clearly 24-3 in reality) statistic. What’s impressive is how House sounds more excited with each “and” he adds to the description of the matchup. To me, each new category decreases the likelihood that the result is meaningful by multiplying the number of prior possibilities. To House, it seems like Denver fitting in such an overly specific description is a coincidence that further reinforces the result.
This is called the conjunction fallacy. I’ll let Eliezer explain:
The conjunction fallacy is when humans rate the probability P(A&B) higher than the probability P(B), even though it is a theorem that P(A&B) <= P(B). For example, in one experiment in 1981, 68% of the subjects ranked it more likely that “Reagan will provide federal support for unwed mothers and cut federal support to local governments” than that “Reagan will provide federal support for unwed mothers.” […]
Which is to say: Adding detail can make a scenario SOUND MORE PLAUSIBLE, even though the event necessarily BECOMES LESS PROBABLE. […]
In the 1982 experiment where professional forecasters assigned systematically higher probabilities to “Russia invades Poland, followed by suspension of diplomatic relations between USA and USSR” versus “Suspension of diplomatic relations between USA and USSR”, each experimental group was only presented with one proposition. […]
What could the forecasters have done to avoid the conjunction fallacy, without seeing the direct comparison, or even knowing that anyone was going to test them on the conjunction fallacy? It seems to me, that they would need to notice the word “and”. They would need to be wary of it – not just wary, but leap back from it. Even without knowing that researchers were afterward going to test them on the conjunction fallacy particularly. They would need to notice the conjunction of two entire details, and be shocked by the audacity of anyone asking them to endorse such an insanely complicated prediction.
Is someone selling you a drug that works only when the patient is old and a woman and Hispanic? A football team that is an underdog and on turf and good at rushing? One “and” is a warning sign, two “ands” is a billboards spelling BULLSHIT in flashing red lights. How about 11 “ands”?
11 “ands” is a level of bullshit that can only be found in one stinky stall of the washrooms of science, the gift that keeps on giving, the old faithful: power posing. After power posing decisively failed to replicate in an experiment with 5 times the original sample size, the authors of the original study listed 11 ways in which the experimental setup of the replication differed from the original (Table 2 here). These differences include: time in poses (6 minutes in replication vs. 2 minutes in the original), country (Switzerland vs. US), filler task (word vs. faces) and 8 more. The authors claim that any one of the differences could account for the failure of replication.
What’s wrong with this argument? Let’s consider what it would mean for the argument to be true. If it’s true that any of the 11 changes to the original setup could destroy the power posing effect, it means that the power posing effect only exists in that very specific setup. I.e. power posing only works when the pose is held for 2 minutes and only for Americans and only after a verbal task and 8 more ands. If power posing requires so many conjunctions, it was less probable to start with than the chance of Amy Cuddy admitting that power posing isn’t real.
The first rule of improv comedy is “Yes, and…” The first rule of statistical skepticism is “And…,no.”
Rule of And…, no – When someone says “and”, you say “no”.

So, uh … that chart sucks. Well, I’m not sure I want to claim you’re dodging your data. But still: why is “simulation number” even on the chart? And why does it have an effect? If you’re just simulating things a bunch of times, shouldn’t your simulations be independent? Unless you just simulated 1000 rounds of treatment (or something similar) and just failed to state that.
LikeLike
I think he meant cumulative number of simulations. That is, the number of simulations performed that he was able to hack to a p value that low or lower.
LikeLike
Maggie is right, and I changed the wording to make it less confusing.
LikeLike
Thanks!
This was an awesome post.
LikeLike
I see “234=24” (with the three italicized) where I assume it should say “234=24″. Then again, I disable scripts in my browser.
LikeLike
Now I see it in my comment as I saw it in the post…
LikeLike
I’m guessing it’s markdown being greedy. Need to escape the asterixes with backslashes maybe? 2*3*4=24
LikeLike
Thanks for catching it, I forgot that when I enabled markdown in the comments I also enabled it in the posts. Anyway, markdown is enabled in the comments!
LikeLike
Huzzah
LikeLike
Actually N random samples from a uniform distribution will have their average spacing be 1/(N+1), 2/(N+1)…N/(N+1).
LikeLike
On one hand it’s really embarrassing that I made this mistake, on the other hand this is exactly why I have a bounty program on catching mistakes. Sean, I have the email you used to post this comment. You can send me a Venmo/Paypal name from that email and I’ll send you $5 for catching the error.
I have updated that section with the correct math explaining why the Bonferroni correction works, and also updated everything for the fact that Bonferroni is not spelled with a double “n”. This is what happens when I’m writing a post in a time crunch before catching an international flight, as I did with this one.
LikeLike